从本文开始,我们来讨论机器学习中非常重要的一类方法——集成学习。
一、什么是集成学习
简而言之,集成学习的思路就是:我们在解决一个问题(如分类问题)的时候,选取多种算法参与预测(如下图中的算法都可以解决分类问题),在多个预测结果中,选择出现最多的预测类别做为该样本的最终预测类别。
在生活的很多场景中,我们都用到了集成学习的思想。例如买某样东西的时候我们往往会找他人推荐,并且综合大多数人的意见来决定是否购买。
二、集成学习的简单实现与 sklearn 中的接口调用
下面我们就通过编码,来实现一个简单的集成学习。新建一个工程,创建一个 main.py 文件,实现如下:
import numpy as np
from sklearn import datasets
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42) #生成一个有500个点的moon数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
#逻辑回归
from sklearn.linear_model import LogisticRegression
log_clf = LogisticRegression()
log_clf.fit(X_train, y_train)
print(log_clf.score(X_test, y_test)) #prints: 0.864
#支持向量回归
from sklearn.svm import SVC
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
svm_clf.score(X_test, y_test)
print(svm_clf.score(X_test, y_test)) #prints: 0.888
#决策树
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=666)
dt_clf.fit(X_train, y_train)
dt_clf.score(X_test, y_test)
print(dt_clf.score(X_test, y_test)) #prints: 0.864
#求三种模型的预测结果,并进行少数服从多数(预测为1的分类器数目大于2)
y_predict1 = log_clf.predict(X_test)
y_predict2 = svm_clf.predict(X_test)
y_predict3 = dt_clf.predict(X_test)
y_predict = np.array((y_predict1 + y_predict2 + y_predict3) >= 2, dtype='int') #转换成整型向量
#打印集成学习分类结果
print(y_predict)
#计算集成学习后的准确率
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_predict)) #prints: 0.896
可以看到,集成学习的准确度为 0.896,提高了算法的预测准确度。
sklearn 同样为我们提供了集成学习的接口,调用的过程也不复杂。紧接着上面的代码,实现如下:
from sklearn.ensemble import VotingClassifier
#构建VotingClassifier
voting_clf = VotingClassifier(estimators=[ #参数 estimators=[ ]:传入需要使用的算法,放在列表中,使用方式类似管道 Pipeline
('log_clf', LogisticRegression()),
('svm_clf', SVC()),
('dt_clf', DecisionTreeClassifier(random_state=666))],
voting='hard') #其中voting传入hard表示采用"少数服从多数"的集成学习方式
voting_clf.fit(X_train, y_train)
print(voting_clf.score(X_test, y_test))
输出结果应该与手动模拟的结果完全一致。以上算法并没有进行调参,在实际使用时,我们应在 VotingClassifier 中传入调参后的算法进行集成学习。
三、Soft Voting
上面我们提到的“少数服从多数”的投票方式被称为 Hard Voting,相应的,还有一种更重要的方式就是 Soft Voting,我们本节就来讨论一下 Soft Voting 到底是怎么一回事。
其实 Soft Voting 背后的想法也非常简单——在很多情况下,少数服从多数并不是最合理的。更合理的投票方式,应该对于不同的人投票是有不同权值的(例如在一些唱歌比赛中,专业评委的投票权重比普通观众更高一些)。下面我们来通过一个例子来具体感受一下 Hard Voting 的局限性。
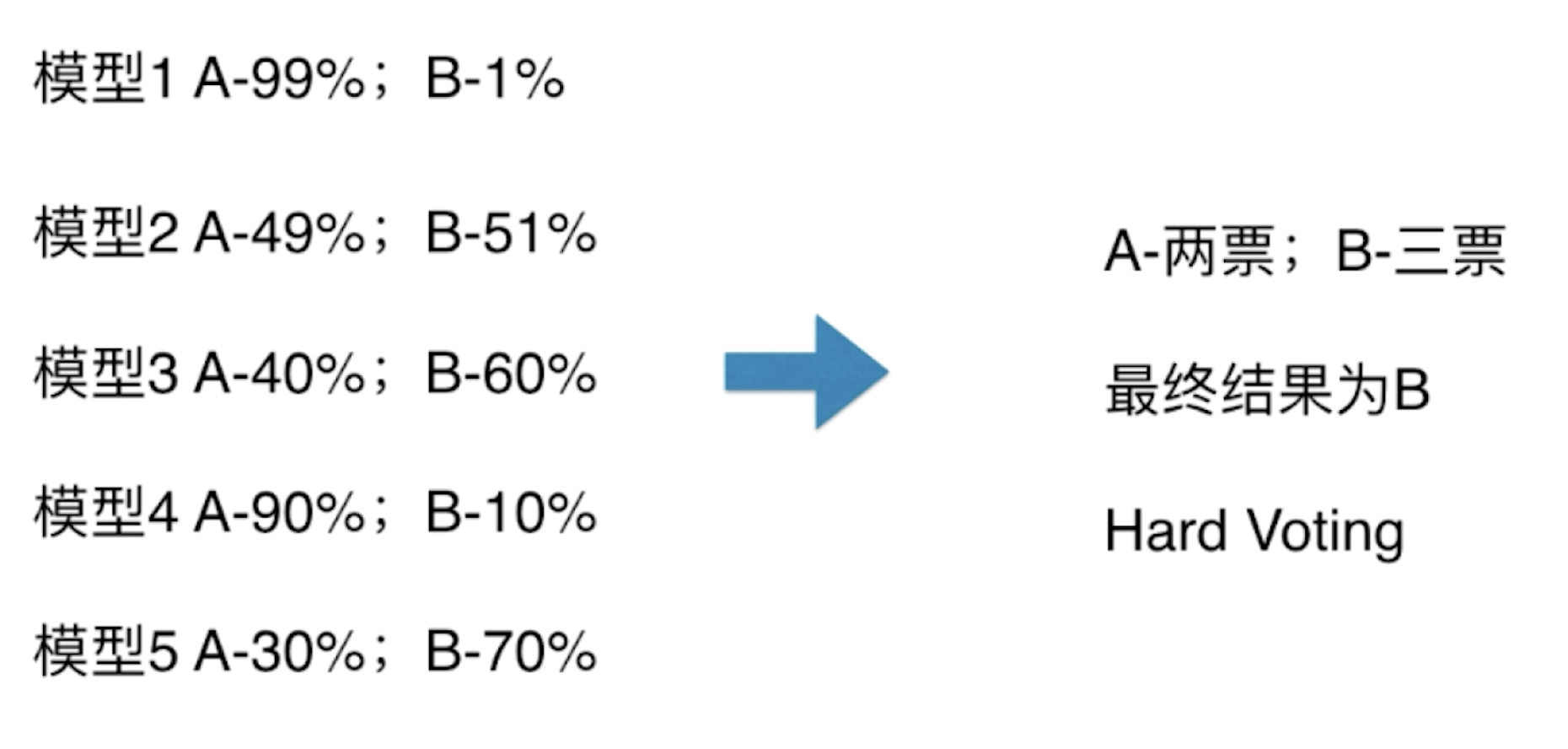
在以上图片的情况中,若我们使用 Hard Voting 来分类,最终结果应该为 B。然而,虽然只有两个模型把数据分成 A 类,但这两个模型几乎是非常确定认为样本就是 A 类(99%、90%);虽然有三个模型把数据分成 B 类,但是它们认为数据为 B 类的概率并不高(51%、60%、70%)。直观来看,虽然把样本数据分成 A 类的票数少,但是感觉它的权值应该更高一些,所谓的 Soft Voting 就是基于这样的考虑。
Soft Voting 做的事情其实是把模型将数据分在不同类的概率当作票数的权值。

Soft Voting 不仅仅看有多少票投给了 A,有多少票要投给 B,与此同时,它还要看那些投给 A 的票,它们到底有多大概率确认样本为 A 类;那些投给 B 的票,它们到底有多大概率确认样本为 B 类。这本身是一个非常自然的思路。
若要使用 Soft Voting,我们就要求集合的每一个模型都必须能估计概率,像之前我们讨论过的逻辑回归、KNN、决策树、SVM 都可以使用 Soft Voting。
逻辑回归本来就是基于概率模型的;kNN算法解决分类问题时,我们采用待预测点数量最多的样本所对应的类别作为最终的预测结果,所以概率可以表示为 p = n/k(其中 n为 k 个样本中,最终确定的类型的个数);对于决策树来说,样本从根结点走到叶子结点,通常在叶子结点中还有多个类别的数据(基尼系数或信息熵不为零),哪个类数据量大,就分为哪一个类。概率的计算与 kNN算法类似,将占比最大的那个类别的数量除以叶子结点中所有数据点的数量;SVM本身比较复杂,计算概率的方式这里就不展开了。在 scikit-learn 中的 SVC() 中的一个参数:probability,设置 SVC(probability=True)时,就能返回样本为各个类别的概率,但是会牺牲一定的计算时间。
下面我们就通过使用 sklearn 的接口来实现一下 Soft Voting,代码如下:
import numpy as np
from sklearn import datasets
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC()),
('dt_clf', DecisionTreeClassifier(random_state=666))],
voting='hard')
voting_clf.fit(X_train, y_train)
print(voting_clf.score(X_test, y_test)) #prints: 0.896
voting_clf2 = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC(probability=True)), #把probability设为true
('dt_clf', DecisionTreeClassifier(random_state=666))],
voting='soft') #更改voting参数为soft
voting_clf2.fit(X_train, y_train)
print(voting_clf2.score(X_test, y_test)) #prints: 0.912
在大部分情况下,Soft Voting 的效果要比 Hard Voting 要好。