前面的几篇文章我们讨论了逻辑回归的一些基本的使用,我们也提到逻辑回归只能解决二分类问题。不过我们可以通过简单的改造,使得逻辑回归算法可以解决多分类问题,具体的改造方法就是所谓的 OvR(One vs Rest) 与 OvO(One vs One)。这两种方法不仅仅只适用于逻辑回归的改造,对于近乎所有的二分类问题,我们都可以用它们来改造以解决多分类问题。本文就将重点探讨 OvR 和 OvO 的原理与和逻辑回归结合的使用。
一、OvR 的原理

OvR(One vs Rest)顾名思义就是“一对剩余”。如上图所示,假设一共有四个类别,对于这样的分类问题我们显然不能直接用逻辑回归来解决。那么我们怎么来解决这个问题呢?相应地,我们选取其中某一个类别,比如选取红色这个类别。对于其它的三个类别,我们将它们融合在一起,统称为“其它类别”:
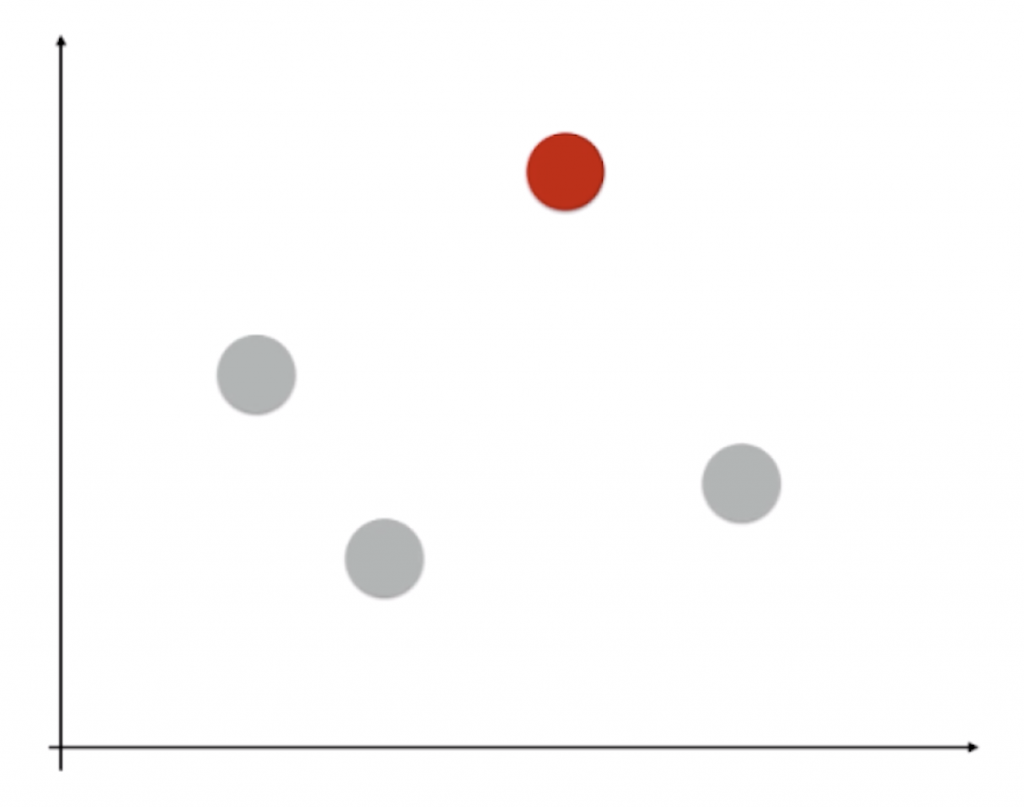
这样我们就把一个四分类问题转化成了二分类问题,现在就能用逻辑回归来估计新的样本点是红色类别的概率和非红色类别的概率了。这个过程同样可以在其它的类别上进行:
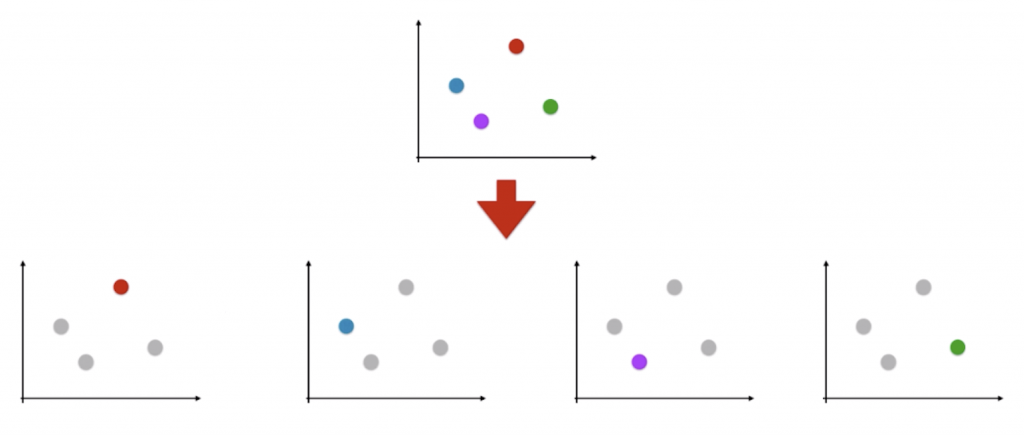
这样,对于每一个二分类任务,我们都能得到新样本点在其中一个类别上对应的概率。进一步拓展,若我们有 n 个类别,我们就能进行 n 次二分类任务,最后选择分类得分(对于逻辑回归来说是判断属于该类别的概率)最高的类别,我们就判断新样本点是属于这个类别的。只不过运用这种方法,算法的复杂度提升了,若处理一个二分类任务的时间为 T,由于一共有 n 个类别,运用 OvR 处理后时间将会变为n · T,时间复杂度为O(n)。
二、OvO 的原理

第二种改造方法被称为 OvO(One vs One),也就是“一对一”。如上图所示,我们每次就挑出两个类别,例如红蓝这两个类别,然后进行二分类任务,看对于这个二分类任务来说新样本点属于红色类别还是蓝色类别,这个过程可以重复进行:
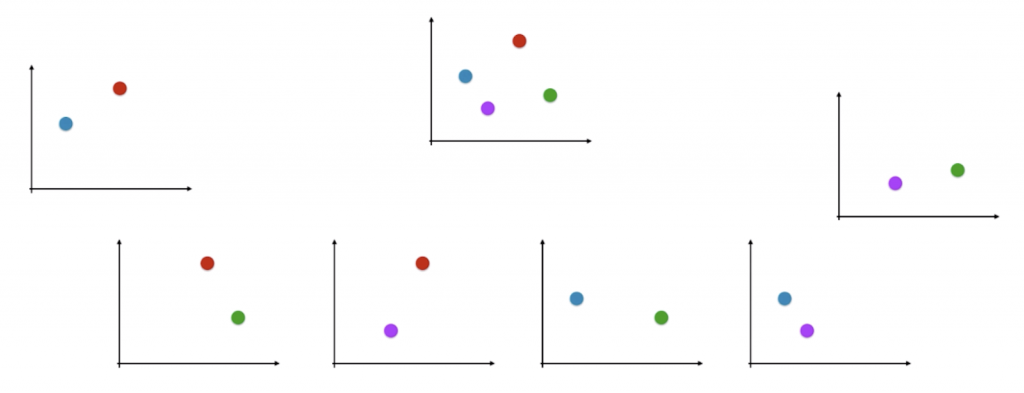
对于每一个二分类问题,我们都能估计新样本点处于这两个类别中的哪个类别。最后对这 6 个分类结果进行投票,看哪个分类结果出现的频率最高,最终就判定新样本在哪个类别。进一步拓展,若我们有 n 个类别,我们就能进行 Cn2 次分类,这些分类结果中出现频率最高的那种样本类型,就被认为是该样本最终的预测类型。对于时间复杂度而言,如果处理一个二分类问题用时 T,运用 OvO 需要用时 Cn2 · T = [n·(n – 1) / 2] · T,时间复杂度 O(n2),效率比 OvR 低一些。
虽然 OvO 用时较多,但其分类结果更准确,因为每一次二分类时都用真实的类型进行比较,没有混淆其它的类别。
三、调用sklearn实现 OvR 和 OvO
新建一个工程,创建一个main.py文件,实现以下代码:
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
#LogisticRegression类默认支持OvR
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
print(log_reg.score(X_test, y_test)) #prints: 0.9473684210526315
#进行OvO
log_reg2 = LogisticRegression(multi_class="multinomial", solver="newton-cg")
log_reg2.fit(X_train, y_train)
print(log_reg2.score(X_test, y_test)) #prints: 1.0
当然,sklearn也有定义单独的 OvR 和 OvO 类,我们只要在它们的构造函数中传入一个二分类的分类器,它就能自动使用对应的方法进行多分类。以逻辑回归为例,实现如下:
from sklearn.multiclass import OneVsRestClassifier
ovr = OneVsRestClassifier(log_reg) #构造函数内传入一个二分类算法对象,就可以进行OvR
ovr.fit(X_train, y_train)
ovr.score(X_test, y_test)
from sklearn.multiclass import OneVsOneClassifier
ovo = OneVsOneClassifier(log_reg) #构造函数内传入一个二分类算法对象,就可以进行OvO
ovo.fit(X_train, y_train)
ovo.score(X_test, y_test)
输出结果应该与上面完全一致。