所谓数据归一化,就是将所有的数据映射到同一尺度,从而便于不同单位或量级的指标能够进行比较和加权。例如,一组数据中包含一个人的年龄与他的年薪两个属性,若我们直接运用kNN算法来建立模型,不难发现数据的变化会被年薪这个属性“主导”(因为年薪的数量级往往比一个人的年龄高很多)。所以在将数据“喂”给我们的机器学习算法之前,对属性进行归一化处理就显得尤为重要。
一、数据归一化处理的两种方式
要对数据进行归一化处理,我们通常有两种方式:
● 最值归一化(normalization),将所有数据映射到0和1之间。适用于分布有明显边界的情况(比如学生的考试成绩),受outlier(极端值)影响较大。
● 均值方差归一化(standardization),将所有数据归一到均值为0、方差为1的分布中,适用于数据分布没有明显边界(有明显边界时也可以使用)、有可能出现极端值的情况。
对于最值归一化,我们有如下的公式: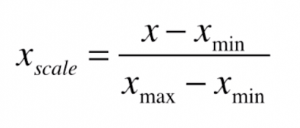
其中,Xmin和Xmax分别表示对应特征值的最小值和最大值。
对于均值方差归一化,类似地,我们的公式是: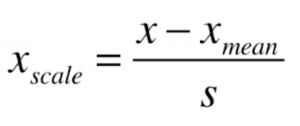
其中,Xmean为对应特征值的均值,S为对应特征值的方差。
二、数据归一化的代码实现
首先我们来看一下对于数据归一化的简单实现:
import numpy as np
x = np.random.randint(0, 100, 100) #生成一个0到100之间含有100个元素的随机array
print(x[:10]) #打印前十个数据
x = (x - np.min(x)) / (np.max(x) - np.min(x)) #进行最值归一化
print(x[:10])
X = np.random.randint(0, 100, (50, 2)) #生成一个50x2的随机矩阵
X = np.array(X, dtype=float)
print(X[:10,:]) #打印前十行
#进行最值归一化
X[:,0] = (X[:,0] - np.min(X[:,0])) / (np.max(X[:,0]) - np.min(X[:,0]))
X[:,1] = (X[:,1] - np.min(X[:,1])) / (np.max(X[:,1]) - np.min(X[:,1]))
print(X[:10,:])
import numpy as np
X2 = np.random.randint(0, 100, (50, 2))
X2 = np.array(X2, dtype=float)
print(X2[:10,:])
#进行均值方差归一化
X2[:,0] = (X2[:,0] - np.mean(X2[:,0])) / np.std(X2[:,0])
X2[:,1] = (X2[:,1] - np.mean(X2[:,1])) / np.std(X2[:,1])
print(X2[:10,:])
#打印归一化后的均值与方差
for i in range(0,2):
print(np.mean(X2[:,i]))
print(np.std(X2[:,i]))
两种归一化的代码的运行结果如下:
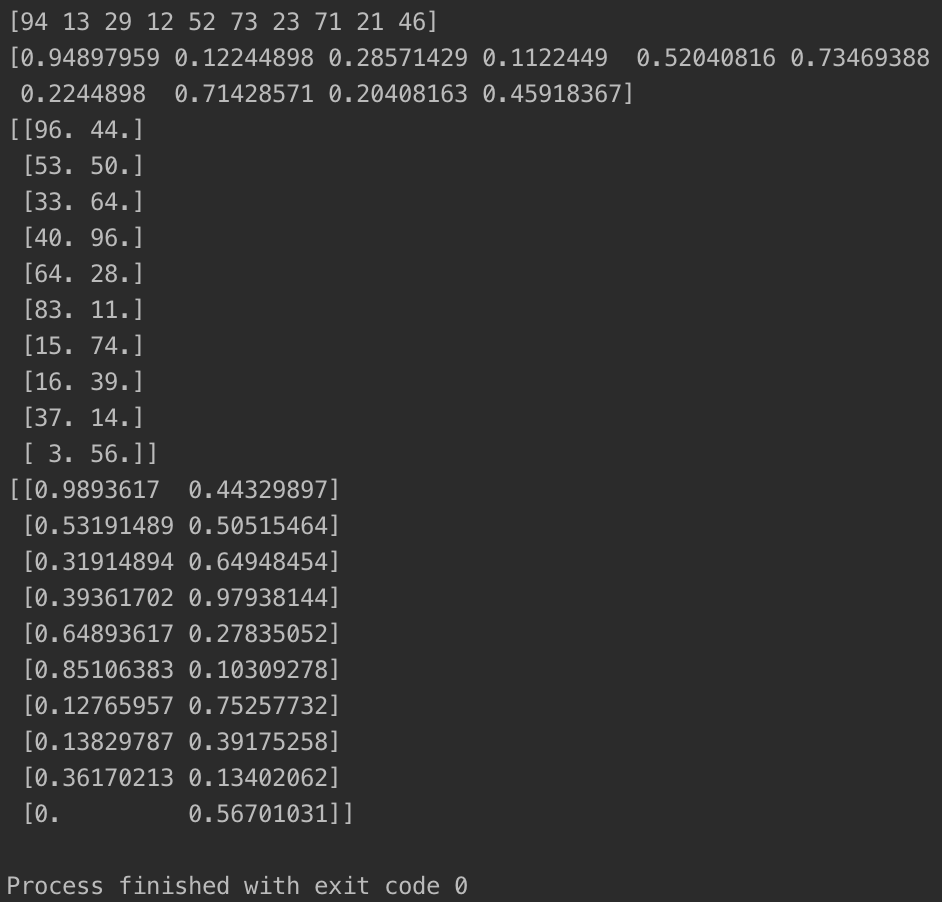
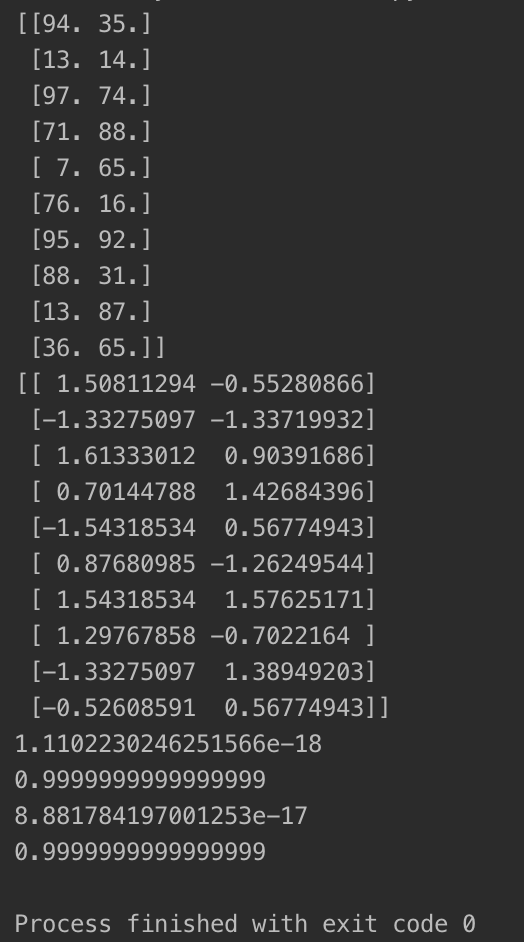
三、调用sklearn库实现数据的归一化
sklearn同样为我们封装好了用于的数据归一化函数,需要使用时直接调用即可。以鸢尾花数据集为例,具体实现如下:
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X[:10,:])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=666)
from sklearn.preprocessing import StandardScaler
standardScalar = StandardScaler() #实例化一个均值方差归一化对象
standardScalar.fit(X_train) #初始化,将数据传入均值方差归一化对象中
print(standardScalar.mean_) #打印各属性均值
print(standardScalar.scale_) #打印各属性方差
print(X_train[:10,:])
X_train = standardScalar.transform(X_train) #对训练集进行归一化处理
print(X_train[:10,:])
print(X_test[:10,:])
X_test_standard = standardScalar.transform(X_test) #对测试集进行归一化处理
print(X_test_standard[:10,:])
"""使用归一化后的数据进行kNN分类"""
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train) #使用归一化后的训练集
print(knn_clf.score(X_test_standard, y_test)) #进行预测时一定要传入归一化后的测试集,否则算法是有问题的
print(knn_clf.score(X_test, y_test)) #如果传入未归一化的测试集,准确率将非常低
这里有一个陷阱,对测试数据集进行归一化处理时,不能直接对测试数据集按公式进行归一化,而是要使用训练数据集的均值和方差对测试数据集归一化,原因有三:
① 真实的环境中,数据会源源不断输出进模型,是无法求取均值和方差的。
② 训练数据集是模拟真实环境中的数据,不能直接使用(无法求出)自身的均值和方差。
③ 在真实环境中,我们无法对单个测试数据进行归一化。
运行后算法的预测准确率如下:
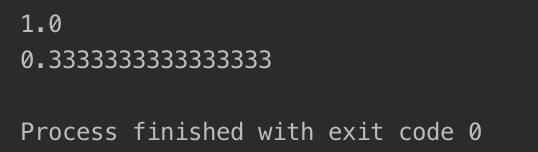
需要重点注意的是,我们在预测的时候一定要在score函数中传入归一化后的数据。从上图我们不难发现,若传入归一化后的数据,算法预测的成功率为100%,而没有传入归一化数据时,算法预测的成功率只有33%,这显然是没有传入归一化数据所导致的。
由于均值方差归一化的适用范围更广,上面的代码只使用了sklearn的StandardScaler类进行数据归一化处理。若我们要使用最值归一化来处理数据,只需要调用MinMaxScaler类即可。调用的步骤是类似的,这里就不再重复了。