一、kNN算法总结
优点:
1、可以解决分类问题,并天然可以解决多分类问题。
2、思想简单,效果强大。
3、同样可以解决回归问题。
缺点:
1、效率低下,若训练集有m个样本,n个特征,则预测每一个新数据的复杂度为O(m*n)。(可用KD-Tree, Ball-Tree优化,但优化后效率仍然不高)
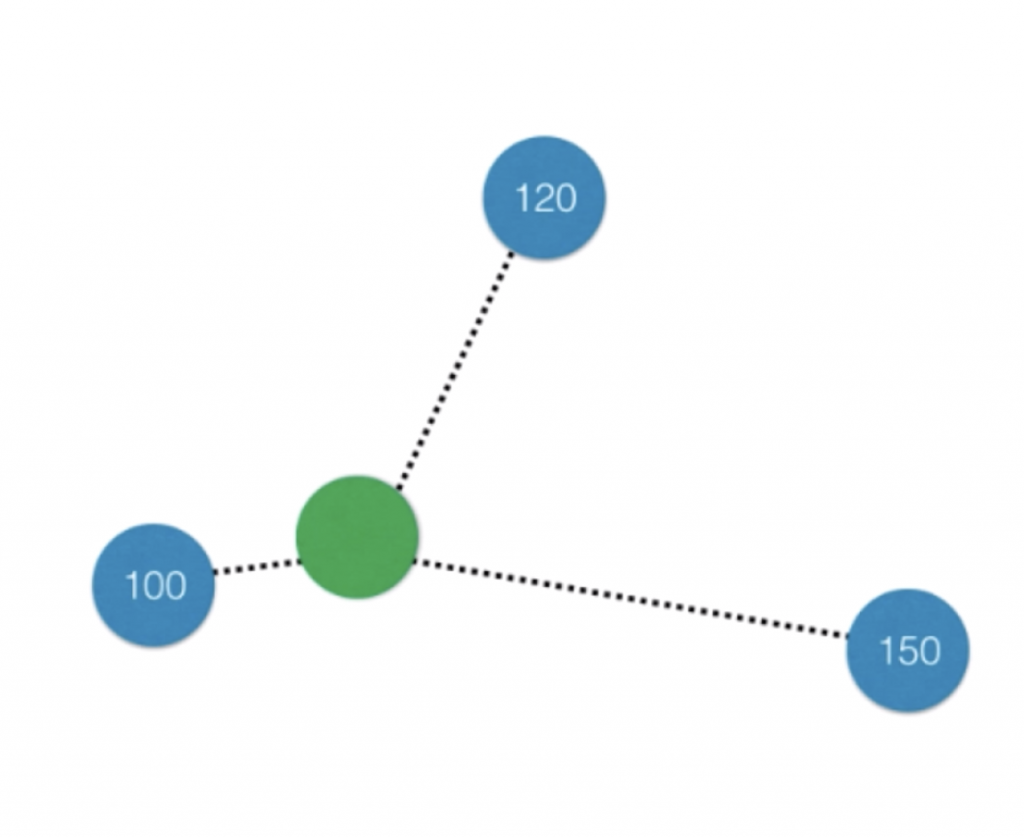
2、高度数据相关、依赖数据,受outlier影响较大。比如三近邻算法,在特征空间中,如果在需要预测的样本周边,一旦有两个样本出现错误值,就足以使预测结果错误,哪怕在更高的范围里,在特征空间中有大量正确的样本。
3、预测结果不具有可解释性。很多情况下,只是拿到预测结果是不够的,还需要对此结果有解释性,进而通过解释推广使用,或者制作更多工具,或者以此为基础发现新的理论/规则,来改进生产活动中的其它方面——这些是kNN算法做不到的。
4、维数灾难:随着维数增加,“看似相近”的两个点距离越来越大。(可以对数据进行降维处理)
二、机器学习流程回顾
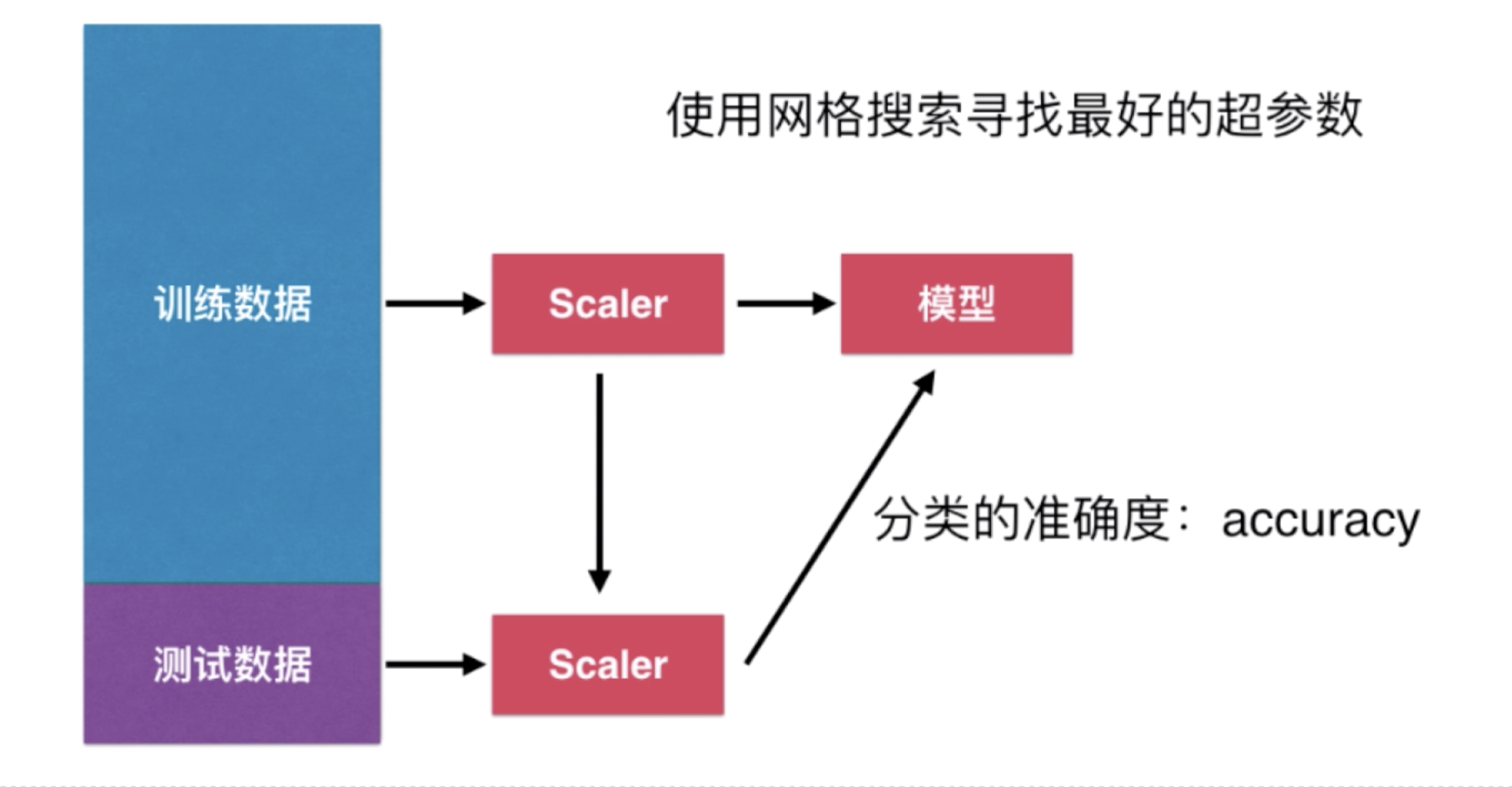
获取原始数据——数据分割——数据归一化——训练模型——预测