之前我们讨论的集成模型的方式都是独立的集成多个模型,对于每个模型我们令它有一定的差异,最终综合这些模型的结果获得学习的最终结果。而本文我们来讨论另一种集成学习的思路——Boosting。
一、什么是 Boosting
顾名思义,Boosting 是“增强、推动”的意思。这种集成学习的思路也是集成多个模型,但与 Bagging 不同的是,Boosting 中的模型不是彼此独立的关系,而是相互增强的关系。集成多个模型,每个模型都在尝试增强整体模型的效果,这种思路就叫做 Boosting。
二、Ada Boosting
我们举一个 Boosting 中最典型的一个例子——Ada Boosting 来说明一下 Boosting 的想法。
以简单的回归问题为例,如下图所示,假设蓝点为原始的数据集,那么我们可以用某种方法对原始的数据集进行学习,拟合结果为红色曲线:
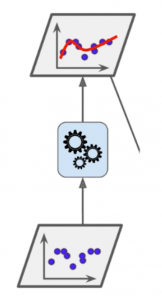
我们使用这个算法学习完一个模型之后,很显然这个模型存在着一定的误差。我们将算法能拟合的点与无法拟合的点分开,就能得到以下结果:
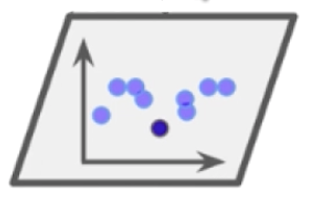
我们让上一个模型中没有很好被学习的点的权重增大一些,让上一个模型中已经很好被学习的点的权重减小一些。这样生成的新的样本数据我们再使用某一种算法进行学习,这次学习中,由于我们调整了权重,所以学习得到的模型与第一次必然有所不同。新模型也会犯一些错误,也会存在一些没能拟合的点,我们就和第一次一样,相应的调整数据点的权重,又可以生成新的模型……如此反复,我们每一次生成的子模型实际上都是想办法弥补上一次生成的模型没有成功拟合的点(每一个子模型都在 Boost 上一个模型所犯的错误)。
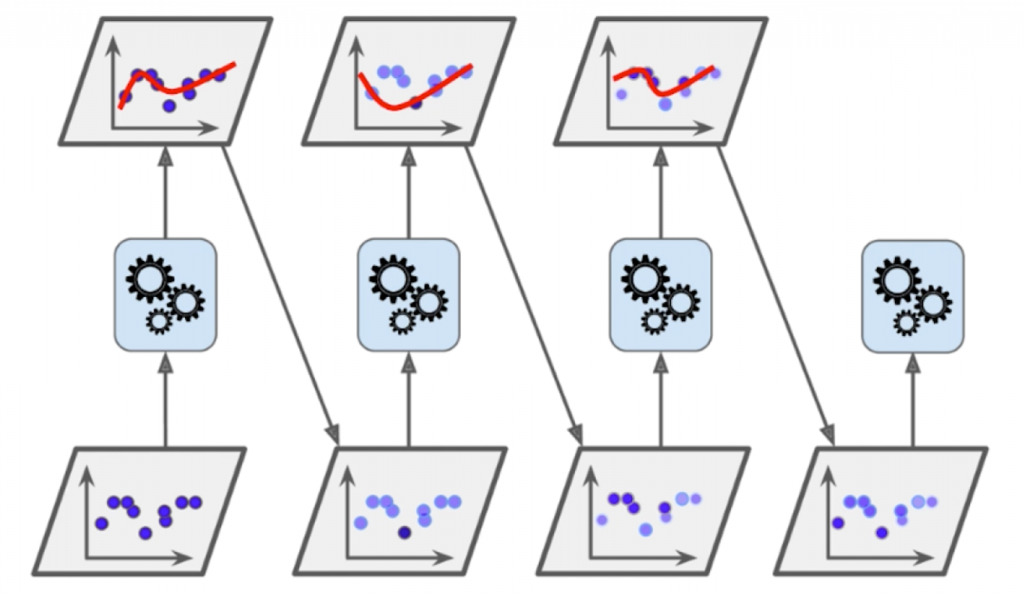
经过这个过程,Ada Boosting 也能生成很多子模型,每一个子模型是基于同样一组样本点,只不过在这些样本点中,点与点之间的权重不同(每个子模型认为哪些点更重要、哪些点不重要的程度不同),所以子模型之间也是有差异的,最终这些子模型投票,来决定 Ada Boosting 的最终学习结果。
对 Ada Boosting来说,怎样为这些数据点附上权重,可以转换为一个求极值的问题。具体的数学推导可参看周志华《机器学习》中的有关内容。
下面我们通过 sklearn 提供的类来实现 Ada Boosting,代码如下:
from sklearn import datasets
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=666)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500) #以决策树为例
ada_clf.fit(X_train, y_train)
print(ada_clf.score(X_test, y_test)) #prints: 0.864
from sklearn import datasets对于 Ada Boosting还有一些其他的参数可以调整,具体可参看 sklearn的文档。
三、Gradient Boosting
另一个常见的 Boosting 算法被称为 Gradient Boosting。它的思想大致是这样的:首先针对整体的数据集训练出一个模型 m1,产生的误差为 e1;之后再针对 e1 训练第二个模型 m2,m2 的作用就是能预测出 m1 犯的错误是什么(m2 的输出值为 m1 犯的错误),m2 拟合 e1 的时候也会犯错误,记为 e2;我们可以拟合 e2 训练出 m3,m3 也会产生误差,记为 e3……以此类推下去,m1、m2、m3 都是对前一个模型所犯错误的补偿,最终我们若要对新数据进行预测,那就是之前训练的一系列模型预测结果之和(m1+m2+m3)。
下面我们简单的来看一个具体的例子,如下图:
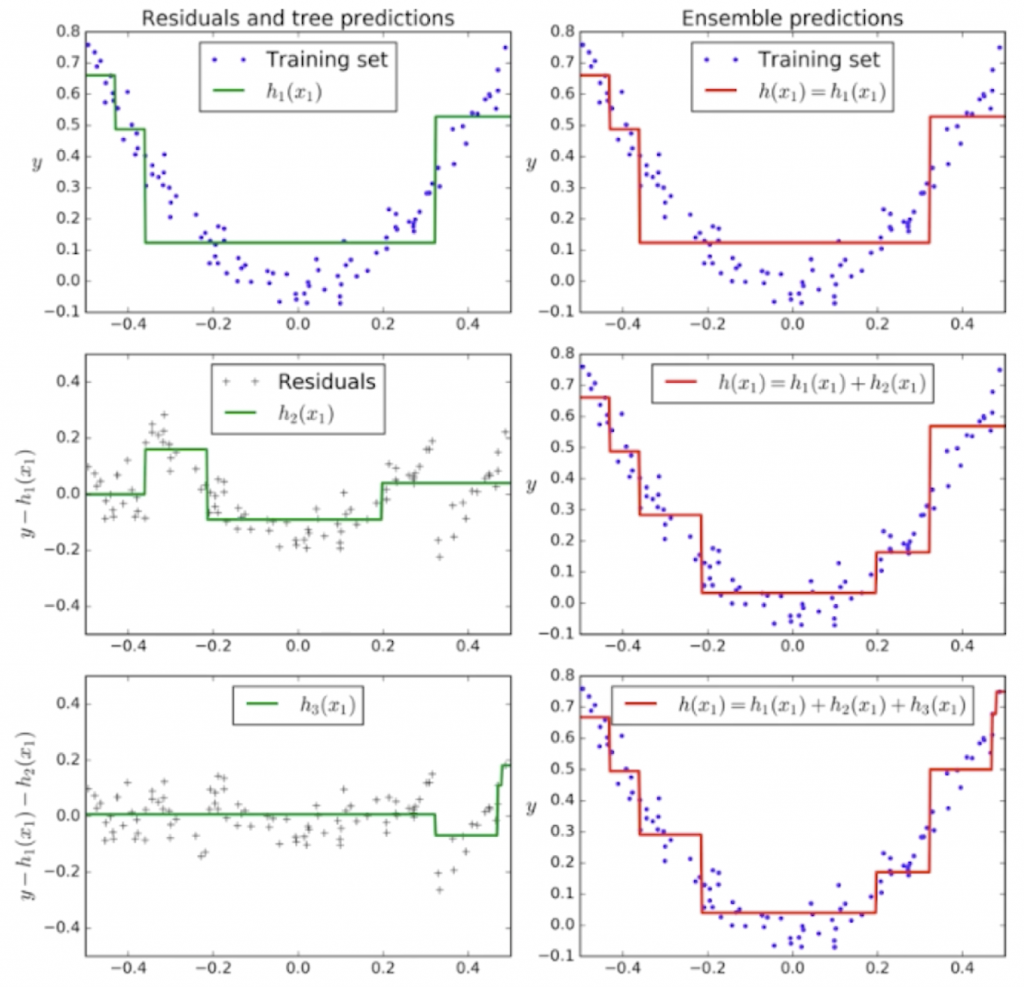
比如原始的数据为随机生成的抛物线(左上角的图),那我们生成的 m1 就是绿色的这条线,对于每一个样本点,绿色的线在预测的时候就会犯错误,犯的错误就是 e1,就在左边中间的这幅图上;将这幅图的数据进行训练,拟合出绿色的直线 m2,而 m1+m2 就是右边中间的那幅图片中的红线,这根线条的拟合程度就比原始 m1 要好很多;e2 所拟合出来的 m3,在与 m1 和 m2 相加后,拟合原始样本点的效果又更进一步了(右下角的图)。
下面我们使用 sklearn 来使用 Gradient Boosting,编码如下:
from sklearn.ensemble import GradientBoostingClassifier
gb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30) #GradientBoostingClassifier以决策树为基础,max_depth=2就是决策树的参数
gb_clf.fit(X_train, y_train)
print(gb_clf.score(X_test, y_test)) #prints: 0.904
对于 Gradient Boosting还有一些其他的参数可以调整,具体可参看 sklearn的文档。
四、Boosting 解决回归问题
和 Bagging 类似,若我们要解决回归问题,只需要加载对应的回归器即可,例如:
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import GradientBoostingRegressor