上文中我们处理 SVM 都是使用线性分类的,也就是假设数据集是线性可分的。本文就着重讨论一下使用多项式特征处理非线性数据的 SVM,并且引出“核函数”的概念。
一、使用多项式特征处理非线性数据
我们首先仿照逻辑回归,使用多项式特征的 SVM 来处理数据,实现如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons(noise=0.15, random_state=666) #加载moons数据集,形状是两个半月形,并加上噪音
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree, C=1.0):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)), #使用多项式特征
("std_scaler", StandardScaler()), #进行标准化
("linearSVC", LinearSVC(C=C))
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X, y)
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(poly_svc, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
由于本文不进行预测,所以没有对数据集进行测试集和验证集的分割。
绘制的决策边界如下:
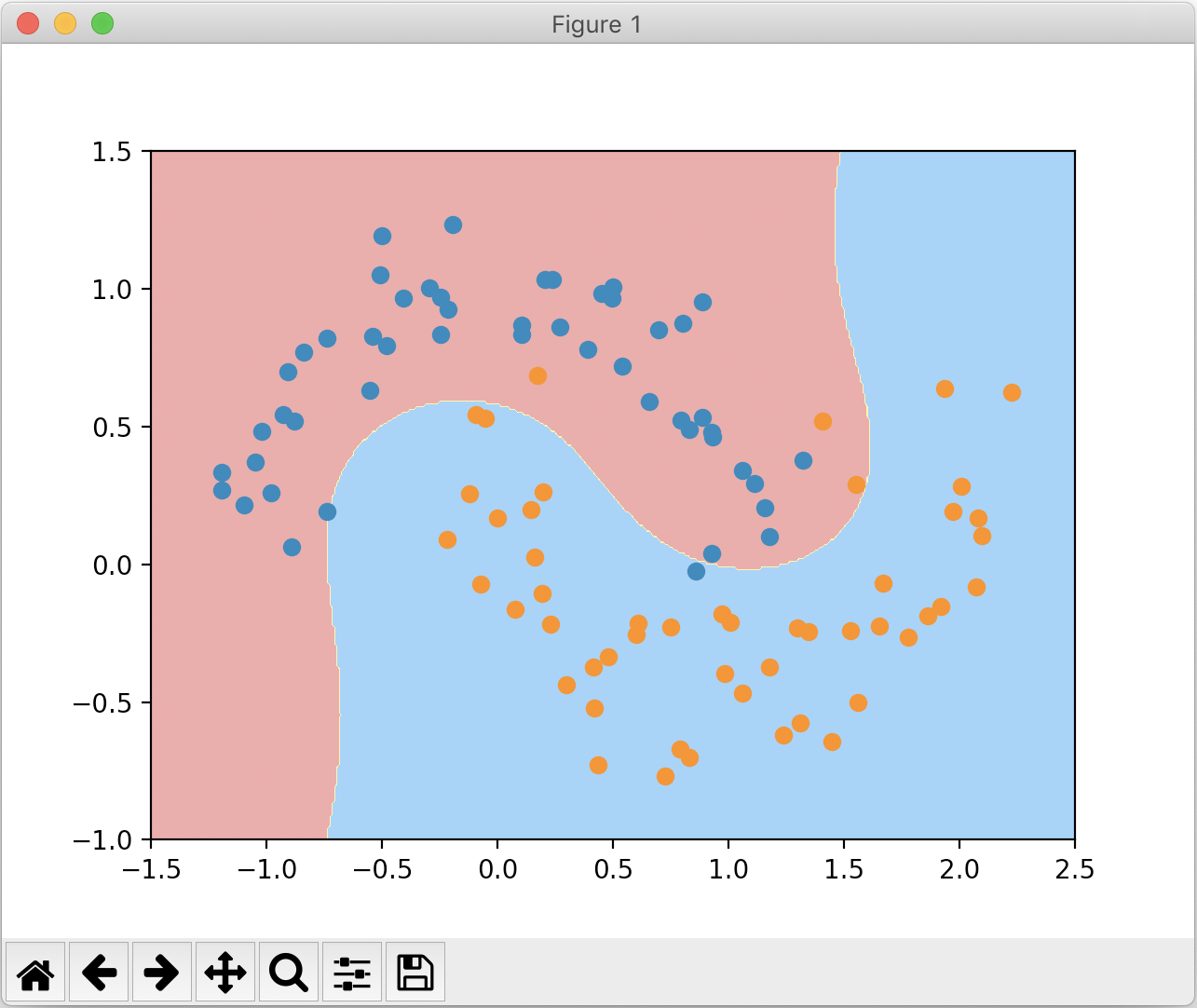
最终运用多项式特征,决策边界变成了一条曲线,我们同样可以改变 degree 和 C 的值来进行调参。
我们使用多项式特征处理非线性问题的原理就是依靠升维,使得原本线性不可分的数据线性可分。
对于 SVM 来说,sklearn 在封装的时候提供了另外一种形式。它不用事先将数据转化成高维的、有多项式项特征的数据,再扔进 LinearSVC 中进行预测, SVM 有一种特殊的方式能直接使用多项式的特征——多项式核。
若我们想用多项式核的 SVM 就需要对代码稍加修改。紧接着上面的代码,实现如下:
from sklearn.svm import SVC #这里直接导入SVC,而不是LinearSVC
def PolynomialKernelSVC(degree, C=1.0):
return Pipeline([
("std_scaler", StandardScaler()),
("kernelSVC", SVC(kernel="poly", degree=degree, C=C)) #核函数传入poly,也就是多项式核的意思
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X, y)
plot_decision_boundary(poly_kernel_svc, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
绘制的决策边界如下:

在这里生成的决策边界虽然与上面的不同,但是总体也是一个非线性的决策边界。我们同样可以调节 C 和 degree,看看不同的参数对决策边界有什么影响。
二、什么是核函数
从上一节我们知道,对于 SVM 有一个很重要的参数 kernel,传入 poly 后,也实现了使用多项式特征实现 SVM 的过程。下面我们以多项式核为例,讨论一下 SVM 中核函数的概念。
我们先来回顾一下 SVM 的目标函数:
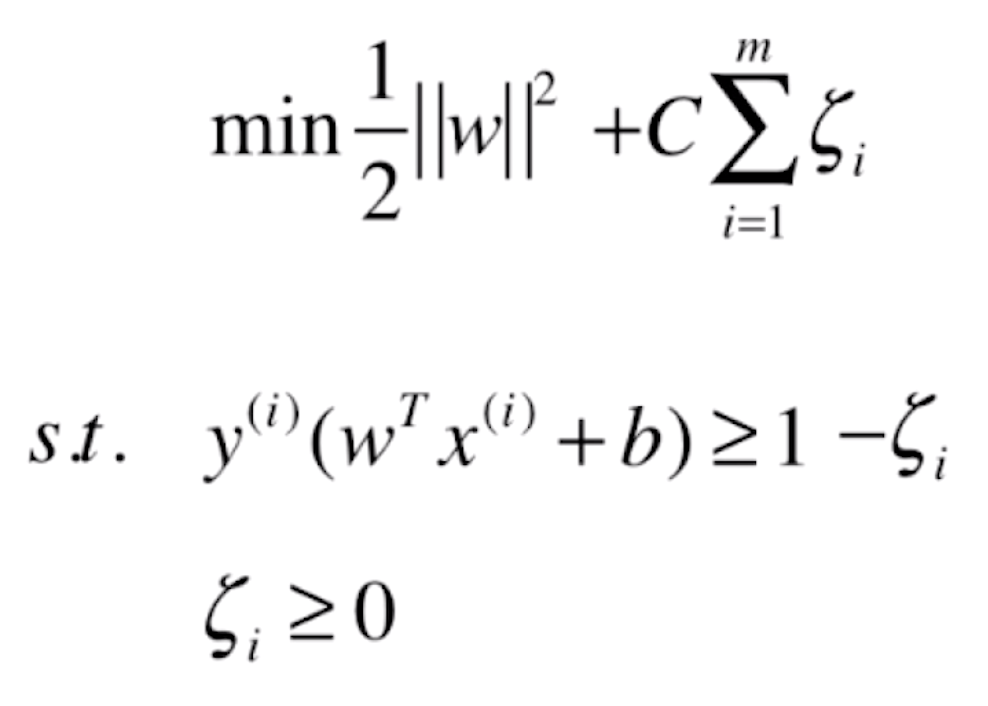
对于上图的最优化问题的推导过程在前一篇文章并没有详细列出,但是它最终会转化成求一个如下的对 α 求极大问题:
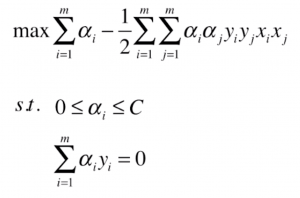
注意到最优化问题最后的 xi · xj,也就是说转换后的最优化问题都要对样本数据集的任意两个向量都要进行向量的点乘。若我们要使用多项式特征,之前一直使用的方式是将原样本 xi 和 xj,添加多项式特征得到新的样本 xi‘、xj‘,并利用新的 xi‘、xj‘ 进行计算。所谓核函数就是不通过引入这个多项式项,直接通过一个函数计算出 xi‘ · xj‘ 的结果,通常这样的核函数记作 K(xi, xj),返回 xi‘ 与 xj‘ 点乘所得到的值,原来求极大问题的 xi · xj 就能直接用 K(xi, xj) 表示。
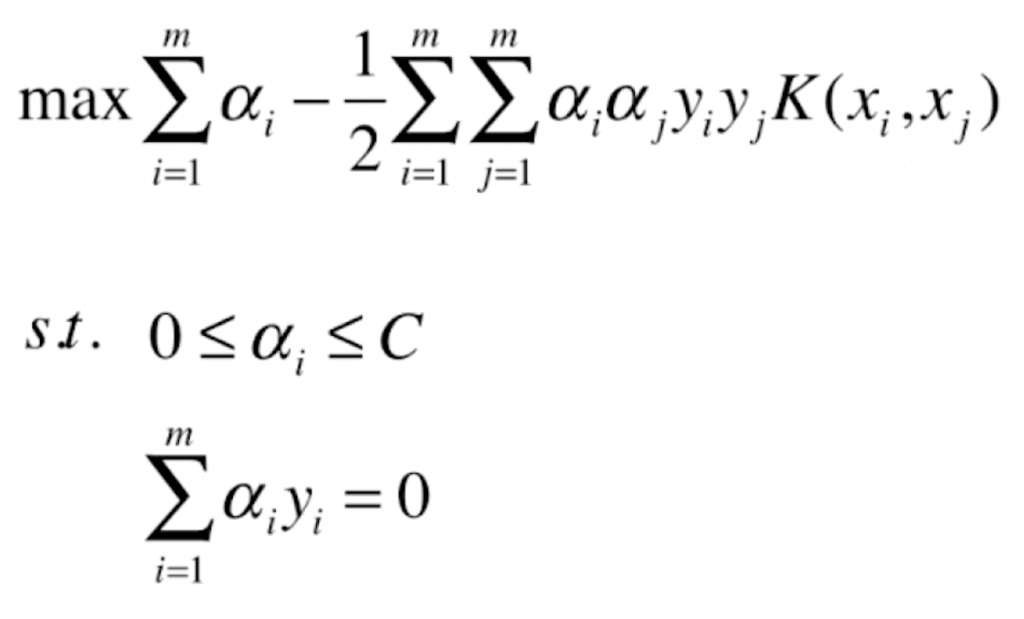
如果我们不使用核函数,也完全可以达到同样的效果。但这里它更像一个数学的技巧:我们把核函数用在这里,就能免去将原来的样本先进行变形、再对变形后的结果进行点乘的步骤。尤其是对于一些复杂的变形,能减小计算量和内存空间。
核函数本身并不是 SVM本身特有的技巧,事实上只要算法可以化成一个最优化问题,在求解这个最优化问题的过程中,存在 xi · xj 这样的式子(或者类似这样的式子),都可以相应的应用核函数技巧。
下面我们以多项式核函数为例,来看一下核函数的运作方式。二次多项式核函数的定义是![]() ,其中 x、y 均为向量。首先把把向量的点乘写成求和的形式,即
,其中 x、y 均为向量。首先把把向量的点乘写成求和的形式,即 ,再进行展开,得
,再进行展开,得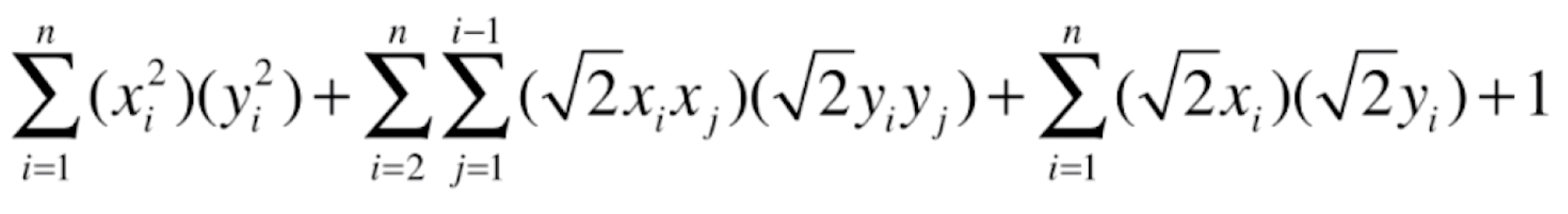 。这个式子就可以看作是若干项相乘再相加(也就是向量点乘的形式),所以原来的 x 是先变成了这样的 x‘:
。这个式子就可以看作是若干项相乘再相加(也就是向量点乘的形式),所以原来的 x 是先变成了这样的 x‘:![]() ,这个向量中包含了从 x1 到 xn 所有的零次到二次的组合形式。相应地,y 也根据这个规律变为类似的形式 y‘,这两个新的向量相乘再相加,结果其实就是 x‘ · y‘( K(x, y) = x‘ · y‘ )。
,这个向量中包含了从 x1 到 xn 所有的零次到二次的组合形式。相应地,y 也根据这个规律变为类似的形式 y‘,这两个新的向量相乘再相加,结果其实就是 x‘ · y‘( K(x, y) = x‘ · y‘ )。
x‘的定义其实就是把原来的样本加上二次项。
对于上面出现的系数根号 2 来说,影响并不大,因为最终我们都会送给线性 SVM 模型进行处理。对于线性 SVM 来说,求的是每一个特征前面的系数,对于这些系数,我们相当于在转换后的新的样本中有一些二次和一次项前面自带一个系数而已,求出的系数不在考虑原来自带的系数即可。以上面的 x‘ 为例,我们完全可以把倒数第二个维度下求出的系数再除以根号 2,以得出正确结果。
综上,核函数的作用就是可以不把二次项变换后的数据表示出来,然后再进行复杂的点乘,而是直接利用原来的样本数据计算,这个结果和我们用变换后 x‘ · y‘ 计算是一致的,这就是核函数的优势,它大大降低了计算的复杂度。
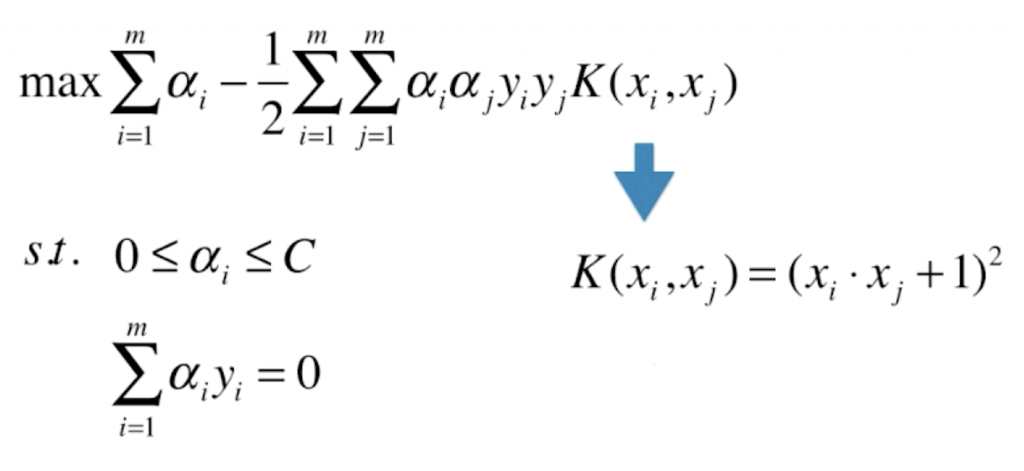
将二次核函数拓展到高次,即![]() ,其中 d 为多项式的次数,c 为一个常数,d 和 c 均为多项式核函数的超参数。
,其中 d 为多项式的次数,c 为一个常数,d 和 c 均为多项式核函数的超参数。
这么一来,线性 SVM的核函数就非常简单,就是 K(x, y) = x · y。
三、高斯核函数 RBF
本节我们来讨论另一种的核函数,它是 SVM 算法使用最多的核函数,也就是所谓的高斯核函数。
在学习概率论时想必大家都了解过正态分布函数,也就是高斯函数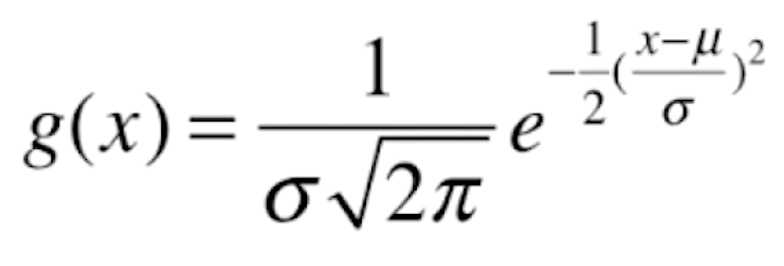 ,我们的高斯核函数和高斯函数非常类似,即
,我们的高斯核函数和高斯函数非常类似,即![]() 。我们可以通过高斯函数的形式来理解高斯核函数的一些性质,具体我们放在后面讨论。
。我们可以通过高斯函数的形式来理解高斯核函数的一些性质,具体我们放在后面讨论。
高斯核函数又被称为 RBF 核(Radial Basis Function Kernel,简称 RBF核),有时候也被叫做径向基函数。我们之前对于多项式核函数,本质就是将所有的的数据点首先添加了多项式项,再将有了多项式项的新的数据特征进行点乘就形成了多项式核函数。相应地,高斯核函数也是将原来的数据点映射为新的、高维的特征向量,然后是这些新的特征向量点乘的结果,只不过高斯核函数表达的数据的映射非常复杂,它将每一个样本点映射到了一个无穷维的特征空间。
高斯核函数对每一个样本点的变形是非常复杂的,但是变形后的结果再进行点乘,得到的答案却是非常简单的,就是
。
先前我们也提到过,我们通常依靠升维使得原本线性不可分的数据线性可分。其实高斯核做的事情也是类似的。以一维数据为例,高斯核函数的表达式是![]() ,在这里我们的 y 不取样本点,而是取两个固定的点 l1 和 l2(l1 和 l2 又被称为地标)。高斯核函数所做的升维过程就是对原本每一个 x 值,若有两个地标,就升为一个二维样本点,每一个样本点的取值为
,在这里我们的 y 不取样本点,而是取两个固定的点 l1 和 l2(l1 和 l2 又被称为地标)。高斯核函数所做的升维过程就是对原本每一个 x 值,若有两个地标,就升为一个二维样本点,每一个样本点的取值为![]() ,这样就把一个一维的样本点映射到了二维的空间,从而变得线性可分。
,这样就把一个一维的样本点映射到了二维的空间,从而变得线性可分。
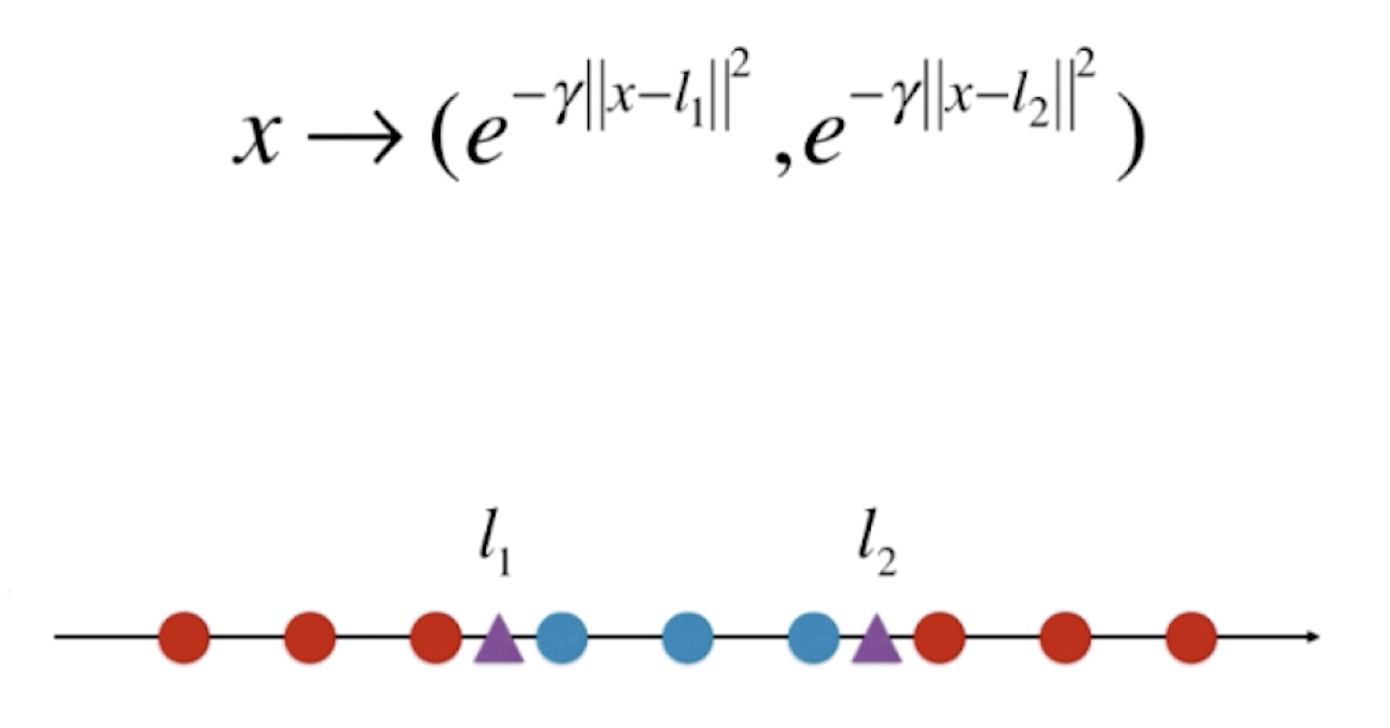
虽然我们把 y 的部分固定成了 l1 和 l2,但是高斯核函数是![]() ,所以 y 的位置其实是每一个数据点。其实高斯核函数做的事和我们之前一样,只不过取得地标点比之前多得多,有多少个样本就取了多少个地标点。也就是说对于每一个样本 x,都要尝试对每一个样本 y 进行这样的核函数计算,成为新的高维数据相对应的某一个维度的元素。所以高斯核函数是将一个 m*n 的数据集,映射为 m*m 的数据集,其中 m 表示样本个数,n 表示原始样本特征种类。样本的个数可以说是无穷的,因此得到的新的数据集的样本也是无穷维的。
,所以 y 的位置其实是每一个数据点。其实高斯核函数做的事和我们之前一样,只不过取得地标点比之前多得多,有多少个样本就取了多少个地标点。也就是说对于每一个样本 x,都要尝试对每一个样本 y 进行这样的核函数计算,成为新的高维数据相对应的某一个维度的元素。所以高斯核函数是将一个 m*n 的数据集,映射为 m*m 的数据集,其中 m 表示样本个数,n 表示原始样本特征种类。样本的个数可以说是无穷的,因此得到的新的数据集的样本也是无穷维的。
使用高斯核函数时的计算开销是非常大的,通常 SVM使用高斯核函数的训练时间会比较长。尽管如此,还是存在一些非常适合使用高斯核函数的应用,最典型的就是初始样本维数特别高、样本数量却并不多(m<n)的时候,使用高斯核函数就非常划算了。典型的领域就是自然语言处理。
现在我们就来讨论一下高斯核![]() 中 γ 的意思。前面我们提到,高斯核和概率论中的正态分布函数的形式是类似的,正态分布有两个参数,一个是 μ ,另一个是 σ,μ 代表均值,σ 代表标准差。μ 决定了高斯函数中心轴的位置,而 σ 描述了样本数据分布的情况:σ 越小高斯分布越窄,样本分布越集中;σ 越大高斯分布越宽,样本分布越分散。
中 γ 的意思。前面我们提到,高斯核和概率论中的正态分布函数的形式是类似的,正态分布有两个参数,一个是 μ ,另一个是 σ,μ 代表均值,σ 代表标准差。μ 决定了高斯函数中心轴的位置,而 σ 描述了样本数据分布的情况:σ 越小高斯分布越窄,样本分布越集中;σ 越大高斯分布越宽,样本分布越分散。
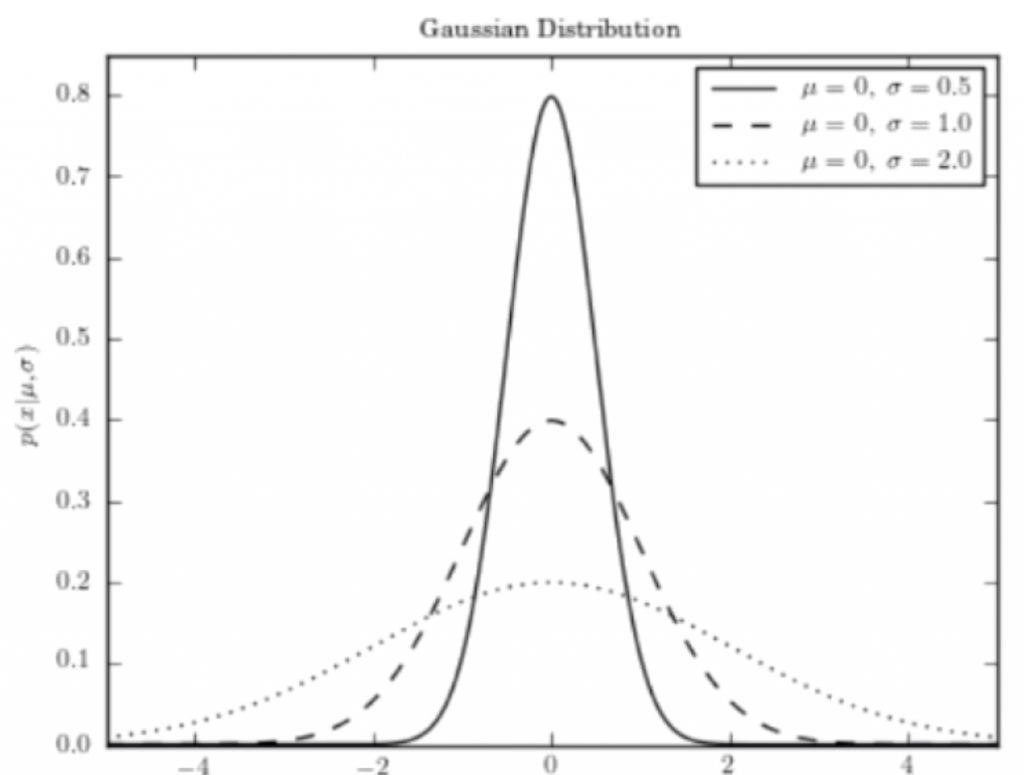
同理,这样的影响对高斯核函数是一致的,只不过高斯函数中,1 / (2σ2) 这一项变成了 γ,所以 γ 的趋势和 σ 是相反的:γ 越大高斯分布越窄,样本分布越集中;γ 越小高斯分布越宽,样本分布越密集。
下面我们就运用 sklearn 封装的 SVM 使用高斯核来进行分类。新建一个工程,创建一个 main.py 文件,实现如下代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons(noise=0.15, random_state=666)
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
def RBFKernelSVC(gamma):
return Pipeline([
("std_scaler", StandardScaler()), #进行标准化处理
("svc", SVC(kernel="rbf", gamma=gamma)) #核函数采用rbf核
])
svc = RBFKernelSVC(gamma=1)
svc.fit(X, y)
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(svc, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
绘制的决策边界如下:
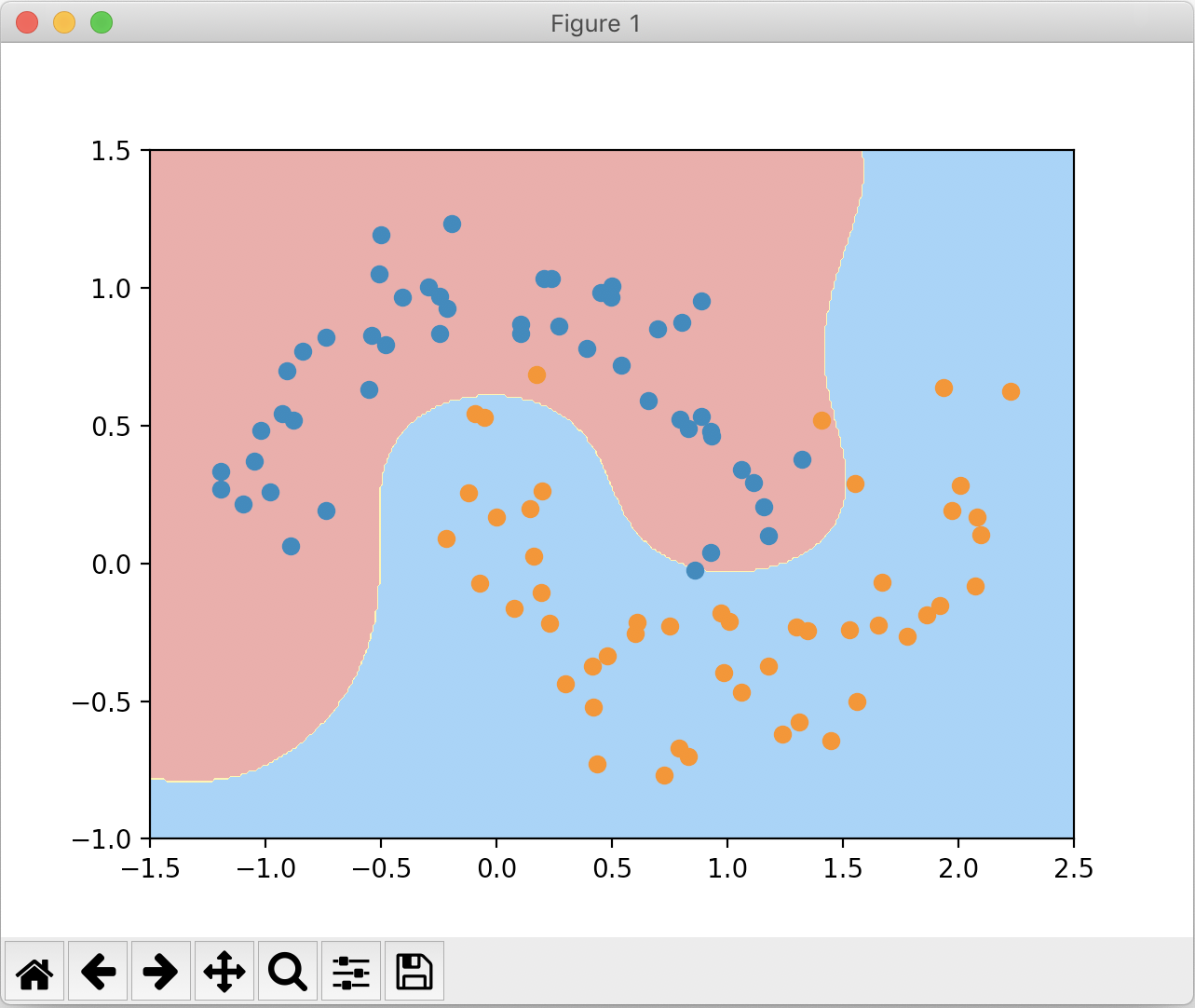
为了寻找 RBF 核的特性,我们分别将 γ 设为 100、10、0.5、0.1,来看一下决策边界的情况:
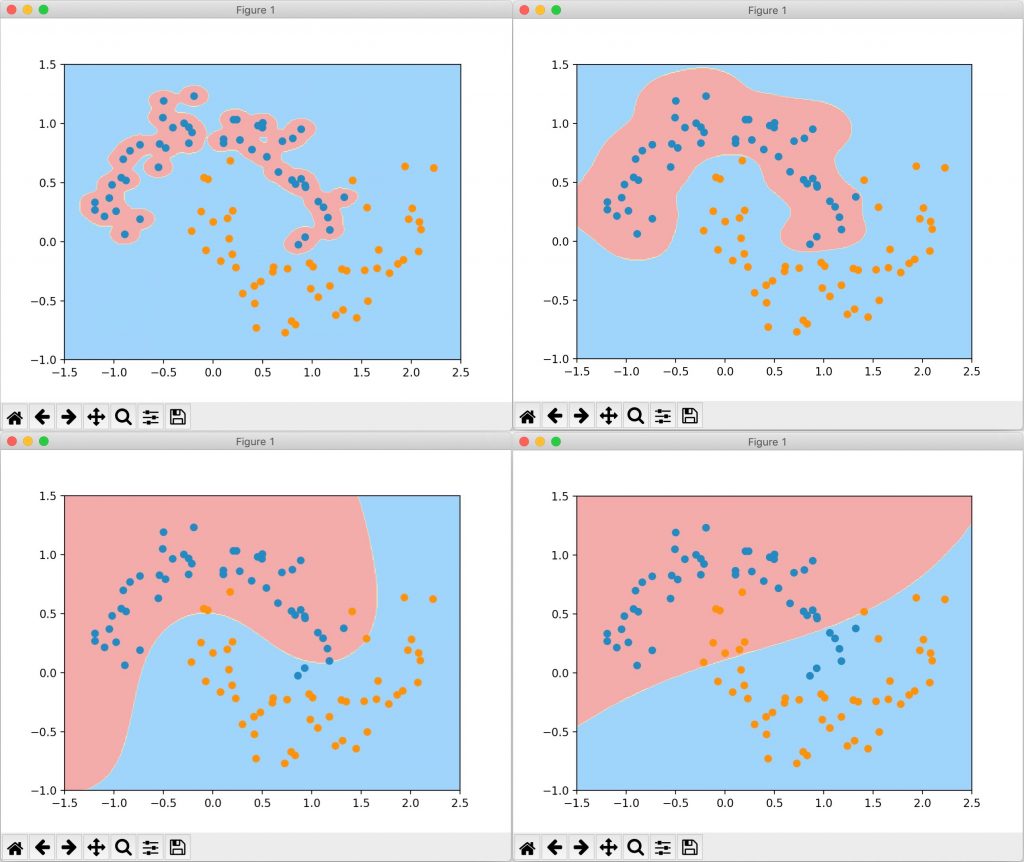
通过观察 RBF 核在不同 γ 下的决策边界,我们可以进一步加以分析。每一个蓝色的样本周围都形成了一个“钟形”的图案,蓝色的样本点是“钟形”图案的顶部,若 γ 的取值过大,样本分布形成的“钟形”图案比较窄,模型过拟合;γ 值过小时,样本分布规律的“钟形”图案变宽,不同样本的“钟形”图案区域交叉一起,形成大片蓝色类型的样本的分布区域,模型欠拟合。超参数 γ 值越小模型复杂度越低,γ 值越大模型复杂度越高。