上文我们讨论了决策树的基本概念,并且利用信息熵和基尼系数两种方式来模拟决策树的划分。其实之前我们实现的决策树又叫 CART(Classification And Regression Tree)。本文我们就来讨论一下 CART 以及 CART 的一些常用的超参数。
一、CART 决策树
CART(Classification And Regression Tree)既可以解决分类问题,又可以解决回归问题,其特点就是根据某一维度 d 和 d 上的某一个阈值 v 进行二分(得到的是一个二叉树),scikit-learn 中的创建决策树的方式就是 CART。
创建决策树的方式有多种:ID3、C4.5、C5.0、CART,ID3 决策树具体在周志华的《机器学习》第四章有详细介绍。
通过之前对决策树在每一个结点上对数据进行划分的模拟,我们整体可以看出,决策树整体做预测的时间复杂度为 O(logm),其中 m 为样本个数。平均来看,每一次在一个节点上划分,都是对当前数据的对半划分,则最终树的高度是 log m ;当传入一个未知的新的样本时,从根节点处开始一步一步做决策,最终走到叶子节点,预测过程不论是分类还是回归,复杂度都是 O(log m)级。但是这样创建决策树训练过程却是 O(n*m*log m)级,因为树是 log m 级别的,如果每一层只划分一个节点,在一个节点上大概都要对数据集做 n*m 次划分,则训练的时间复杂度为 O(n*m*log m),这个训练的复杂度是比较高的。
二、CART 的超参数
更重要的是决策树有一个很大的问题就是它非常容易产生过拟合(事实上所有的非参数学习算法都非常容易产生过拟合的问题),基于这些原因,我们在创建决策树的时候就必须进行剪枝。剪枝有两个目的:降低复杂度和解决过拟合。在 sklearn 封装好的 CART 中,所谓的剪枝就是对一些参数进行平衡,下面我们就通过修改参数来解决过拟合的问题,实现如下代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons(noise=0.25, random_state=666) #随机生成数据
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier() #起始不传参数,也不设置max_depth
dt_clf.fit(X, y)
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(dt_clf, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
dt_clf2 = DecisionTreeClassifier(max_depth=2) #传入最大深度为2的限制
dt_clf2.fit(X, y)
plot_decision_boundary(dt_clf2, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
dt_clf3 = DecisionTreeClassifier(min_samples_split=10) #一个节点至少要有多少样本数据才进行拆分
dt_clf3.fit(X, y)
plot_decision_boundary(dt_clf3, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
dt_clf4 = DecisionTreeClassifier(min_samples_leaf=6) #一个叶子节点最小的样本数
dt_clf4.fit(X, y)
plot_decision_boundary(dt_clf4, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
dt_clf5 = DecisionTreeClassifier(max_leaf_nodes=4) #对一个决策树来说最多有几个叶子节点
dt_clf5.fit(X, y)
plot_decision_boundary(dt_clf5, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
在剪枝之前,绘制的决策边界如下:
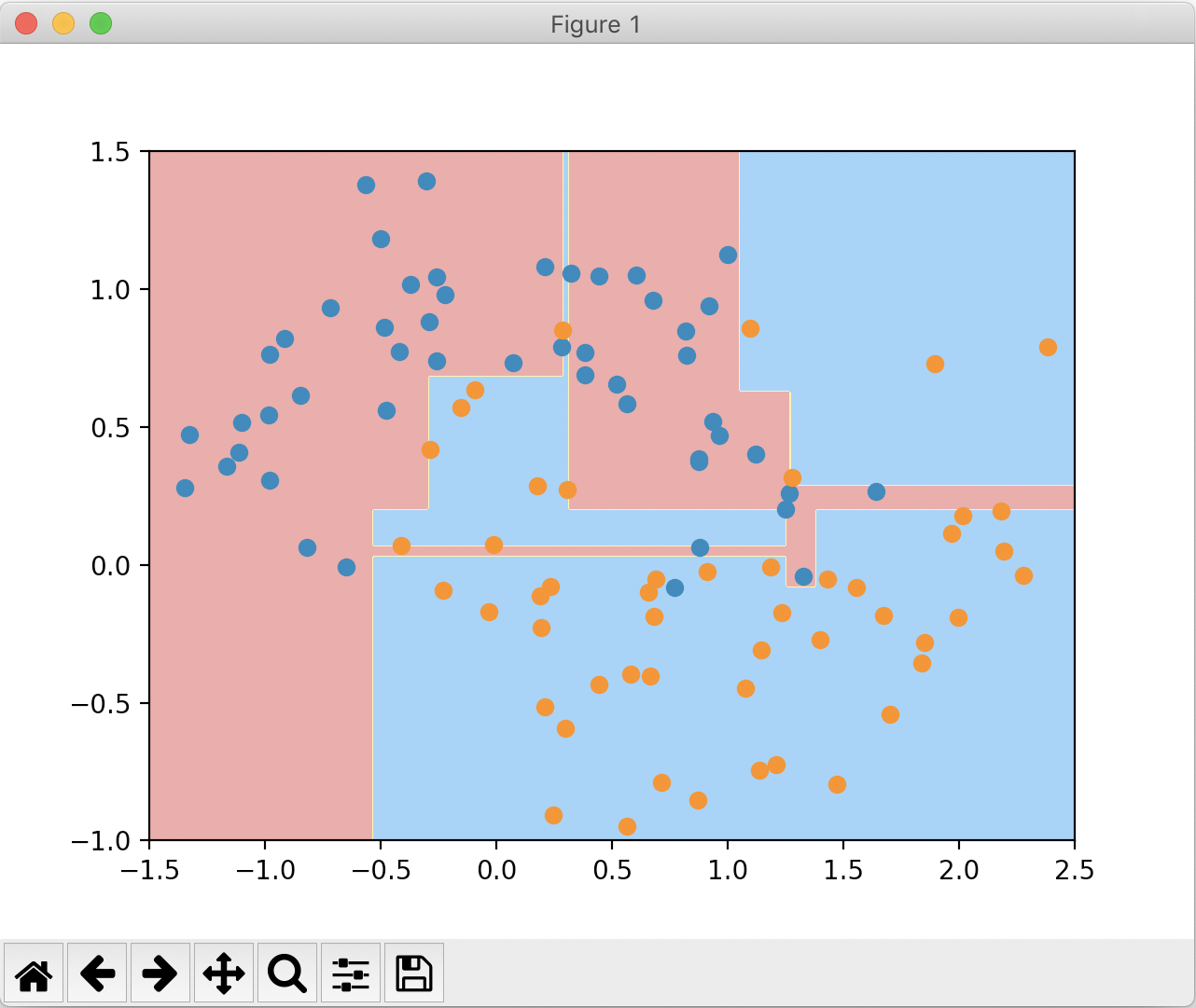
在调整一系列参数进行剪枝后,绘制的决策边界分别如下:
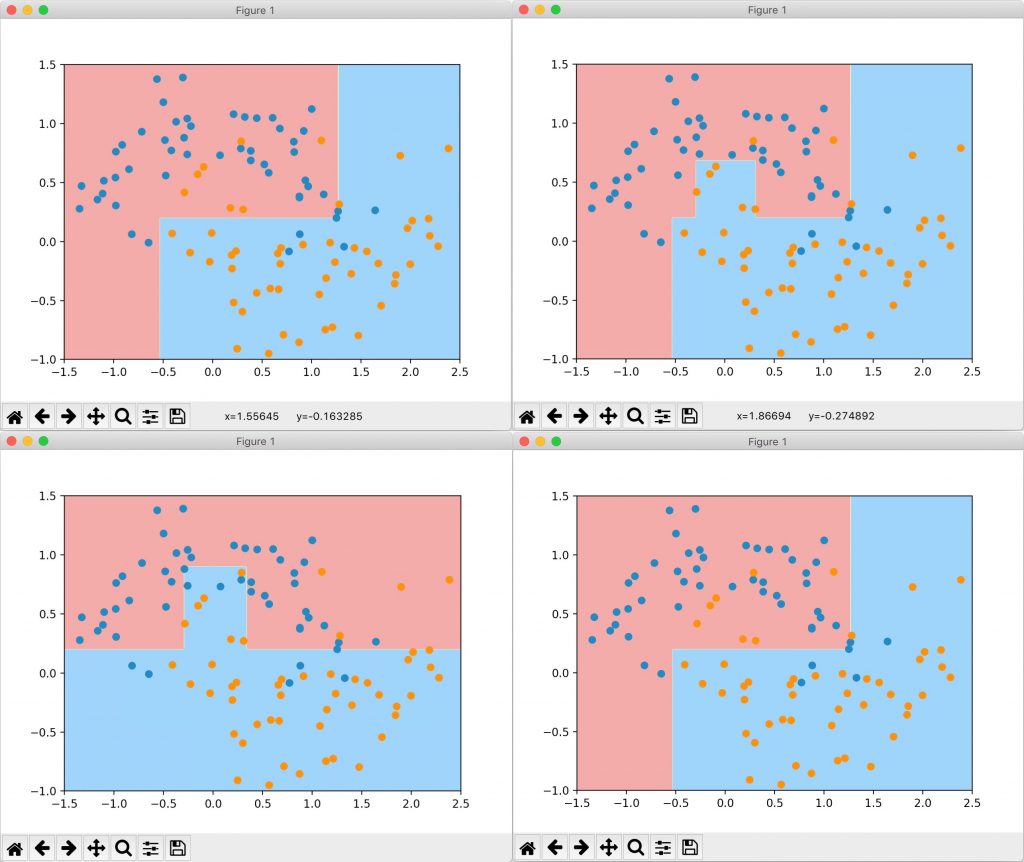
当然,除了上面列出的参数,sklearn中还有其他的超参数可供调整(例如min_weight_fraction_leaf,叶节点最小样本权重总值、max_features,分裂时考虑的最大特征数),可以查阅官方文档来查看。