决策树(Decision Tree)是一种非参数的监督学习算法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。下面我们就来简单讨论一下决策树的基本概念。
一、什么是决策树
其实决策树的思想在日常生活中非常常见。以某企业招聘机器学习算法工程师为例,可以画出以下的思维逻辑:
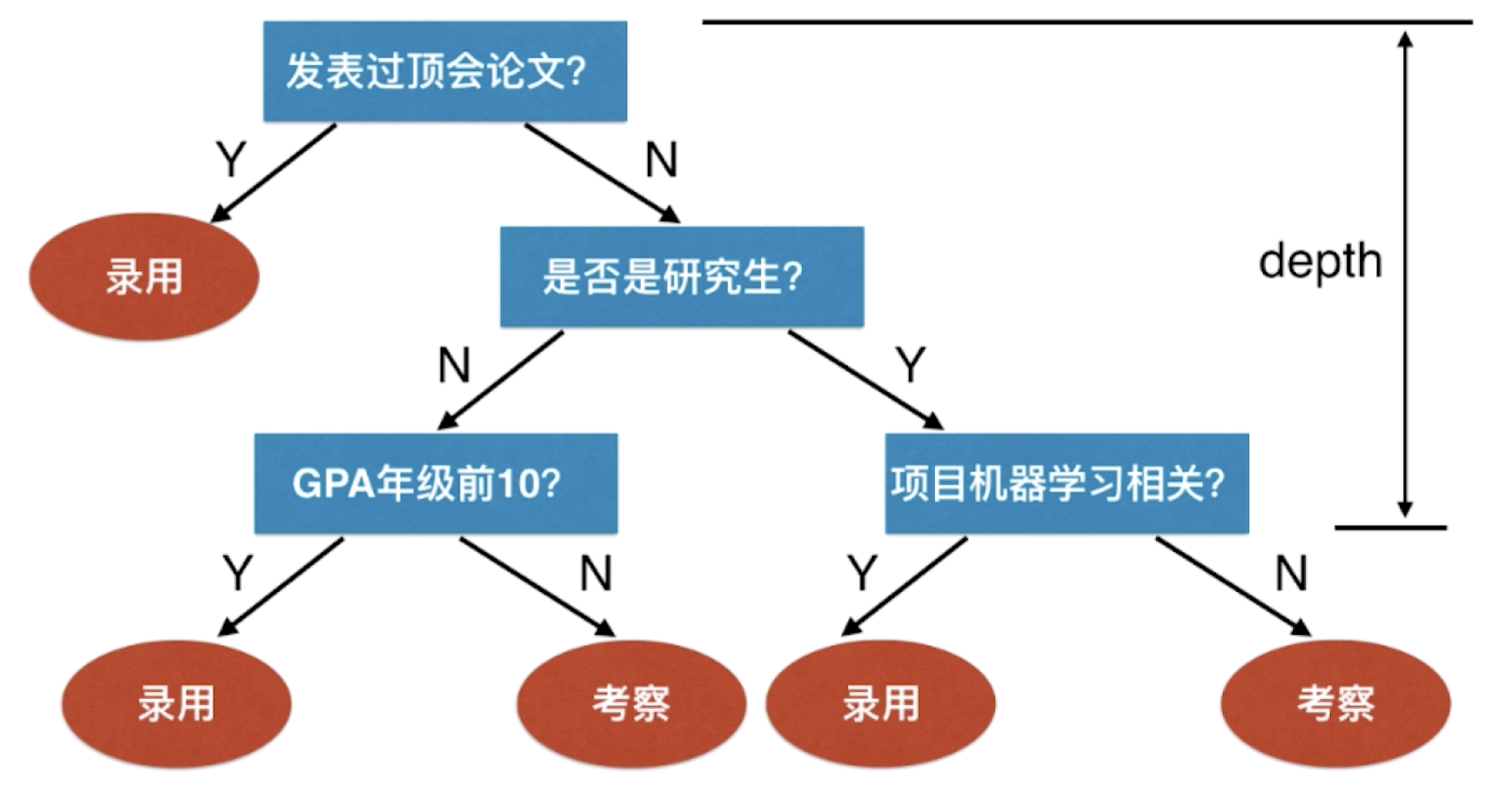
决策树思维是一种逻辑思考方式,逐层的设定条件对事物进行筛选判断,每一次刷选判断都是一次决策,最终达到目的;整个思考过程,其逻辑结构类似分叉的树状,因此称为决策树思维。
从上面的图示可以看出,我们在每一个节点进行决策的时候判断的属性都是可以用 yes 或者 no 来回答。下面我们直接调取sklearn中封装好的决策树算法,并绘制出它的决策边界,初步看一下决策树对于一些判断条件具体数值的表示方法。
新建一个工程,创建一个main.py文件,实现以下代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,2:] #保留鸢尾花数据集的后两个特征
y = iris.target
#导入决策树类
from sklearn.tree import DecisionTreeClassifier
#实例化一个决策树
dt_clf = DecisionTreeClassifier(max_depth=2, criterion="entropy", random_state=42)
"""其中max_depth:决策树最高深度,criterion='entropy':表示“熵”的意思"""
dt_clf.fit(X, y)
#绘制决策边界
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.scatter(X[y==2,0], X[y==2,1])
plt.show()
import numpy as np绘制出来的决策边界如下:
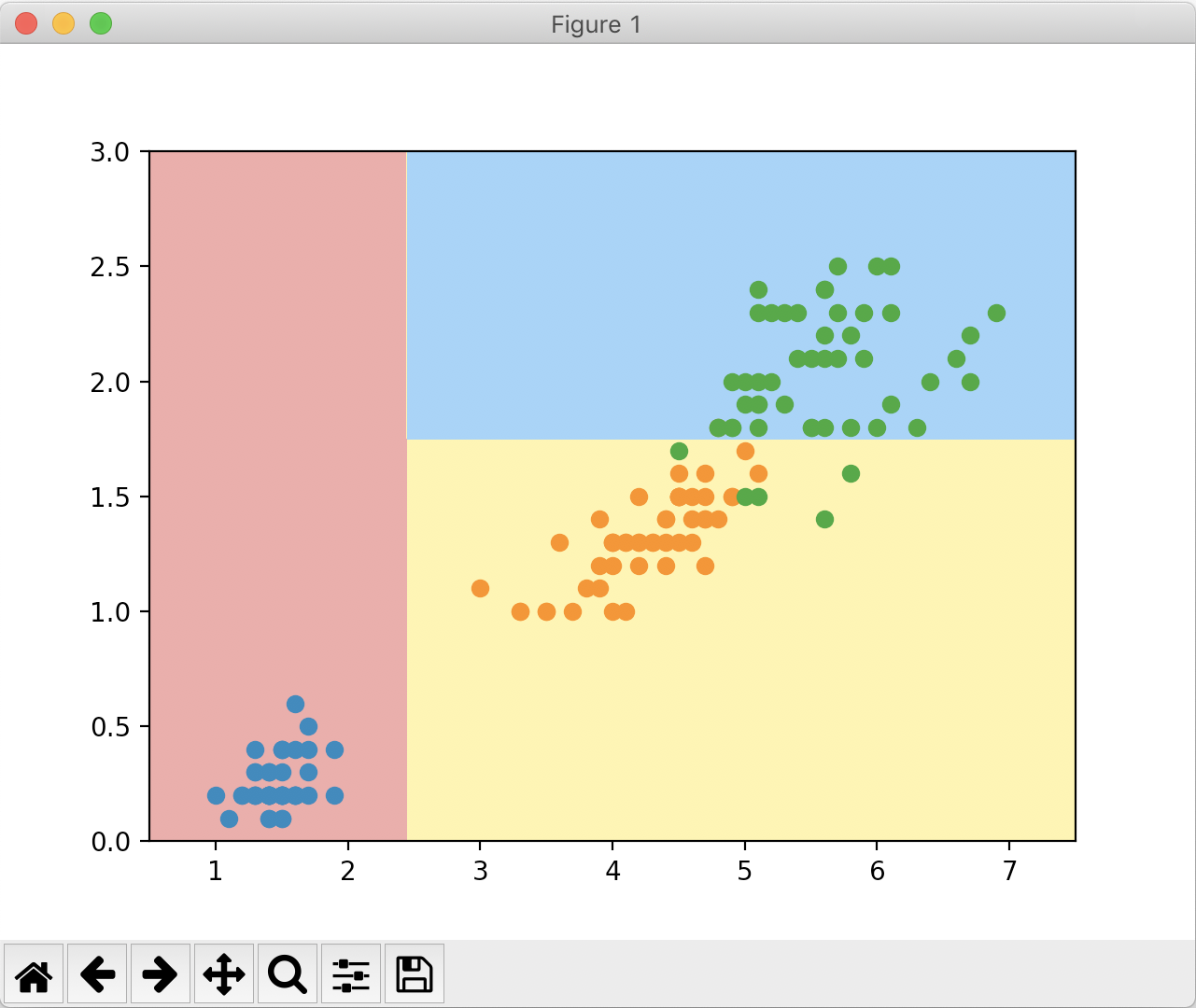
下面我们通过这个图像大概分析一下得到的决策树大概是什么样子。我们把图像横轴称为 x,纵轴为 y,算法首先判断一个点的 x 是否小于 2.4。若小于,直接把点分成 A 类(蓝色点红色区域);否则再判断一个点的 y 是否小于 1.8。若小于,直接把这个点分成 B 类(橙色点黄色区域);否则就把这个点分成 C 类(绿色点蓝色区域)。
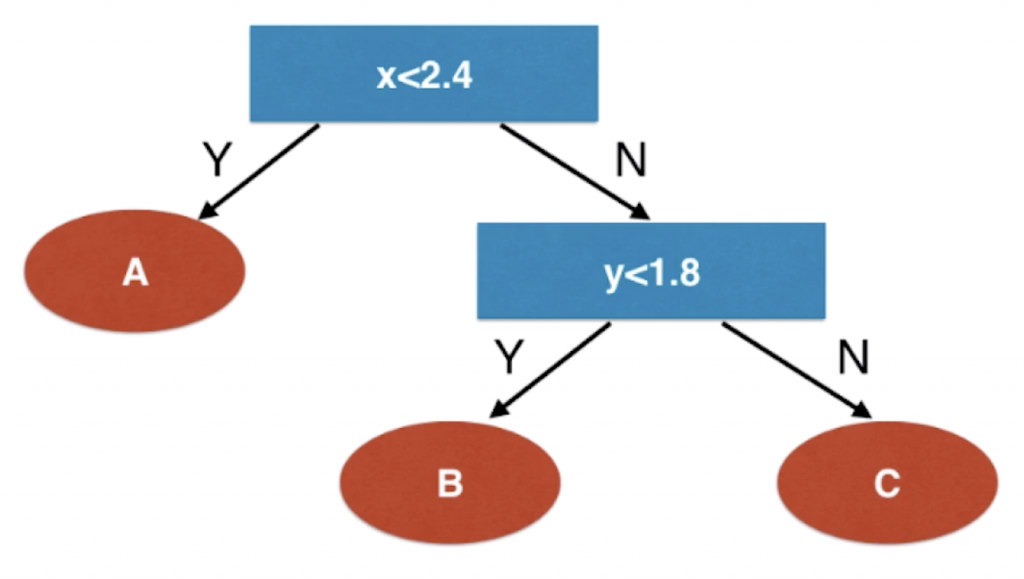
从而我们可以看出,决策树面对属性是数值特征时的处理方法:在每一个节点上,选择某一个维度以及和这个维度相应的一个阈值,比如在根节点选择了 x 这个维度和 2.4 这个阈值,通过判断 x 是否小于 2.4 把它分成两支;在大于等于 2.4 时,又分成了两支,以 y 是否大于 1.8 进行分类。
通过这个例子,我们可以简单总结一下决策树的特征:
1、是一个非参数学习算法。
2、可以解决分类问题,并且天然可以解决多分类问题。
3、也可以解决回归问题(用落在叶子节点中的所有样本数据的平均值作为回归问题的预测值)。
4、具有非常好的可解释性(把样本数据分成某一类的依据)。
二、信息熵
从上一节我们可以看到,决策树构建的关键的问题就是每一个节点找到一个维度和阈值,然后以该维度和阈值为依据判断、进行划分。那我们到底在哪个节点哪个维度进行划分(虽然上图中只有两个维度,但数据复杂的时候有成百上千的维度)?若我们选好了一个维度,又应该在哪个值上进行划分(小于 2.4 分成 A 类还是小于 2.8 分成 A 类)?这就涉及到了计算信息熵的问题。
整体而言,信息熵是随机变量不确定度的度量,是信息论中的代表。对于一组数据来说,它越不确定(越随机),那么它的信息熵就越大;一组数据越确定(不确定性越低),那么它的信息熵就越小。一个系统信息熵的计算可以给出以下公式:
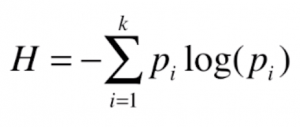
● 其中 Pi 是指对于一个系统中,有 k 类(数据集中样本的总类数)的信息,每一类信息所占系统的比例。(例如鸢尾花数据集中,一共有三种鸢尾花,则三种鸢尾花 P1 、P2 、P3 的值均为 1/3)
● 公式中最前面的负号是由于 Pi < 1,则 log(Pi) < 0。为了让二熵的值 H 大于 0,前面加了负号。
例如我们数据集中有 3 个类别,3 个类别占比各为1/3,此时信息熵的计算结果可以直接代入公式得 ,约为1.0986;我们还可以换一组数据,将三个类别的占比调成
,约为1.0986;我们还可以换一组数据,将三个类别的占比调成 ,继续代入公式得
,继续代入公式得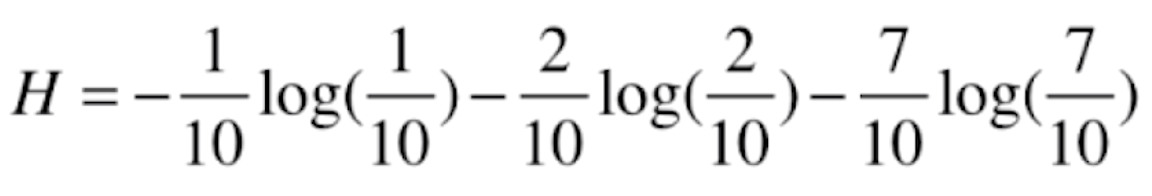 ,结果约为0.8018。显然前一组数据的信息熵比后一组要大,也就是说后一组数据更加“确定”:很多数据都在第三类里,占了 70% 多,所以后一组数据更确定;前一组数据每组各占 1/3,所以整体的不确定性要高一些。我们可以再极端一些,将三个类别占比调成
,结果约为0.8018。显然前一组数据的信息熵比后一组要大,也就是说后一组数据更加“确定”:很多数据都在第三类里,占了 70% 多,所以后一组数据更确定;前一组数据每组各占 1/3,所以整体的不确定性要高一些。我们可以再极端一些,将三个类别占比调成![]() ,那么信息熵就是
,那么信息熵就是![]() ,是该公式的最低值,不确定性是最低的(所有数据都在一类中)。
,是该公式的最低值,不确定性是最低的(所有数据都在一类中)。
我们以二分类问题为例,其中一类占得比例为 p,那么另一类占得比例必为 1-p,此时的信息熵就是![]() 。我们此时就使用Python来绘制一下信息熵函数的图像。新建一个工程,创建一个main.py文件,实现如下:
。我们此时就使用Python来绘制一下信息熵函数的图像。新建一个工程,创建一个main.py文件,实现如下:
import numpy as np
import matplotlib.pyplot as plt
def entropy(p):
return -p * np.log(p) - (1-p) * np.log(1-p)
x = np.linspace(0.01, 0.99, 200) #这里不取0到1是因为要避免绘制对数函数真数为0的情况
plt.plot(x, entropy(x))
plt.show()
得到的图像如下:
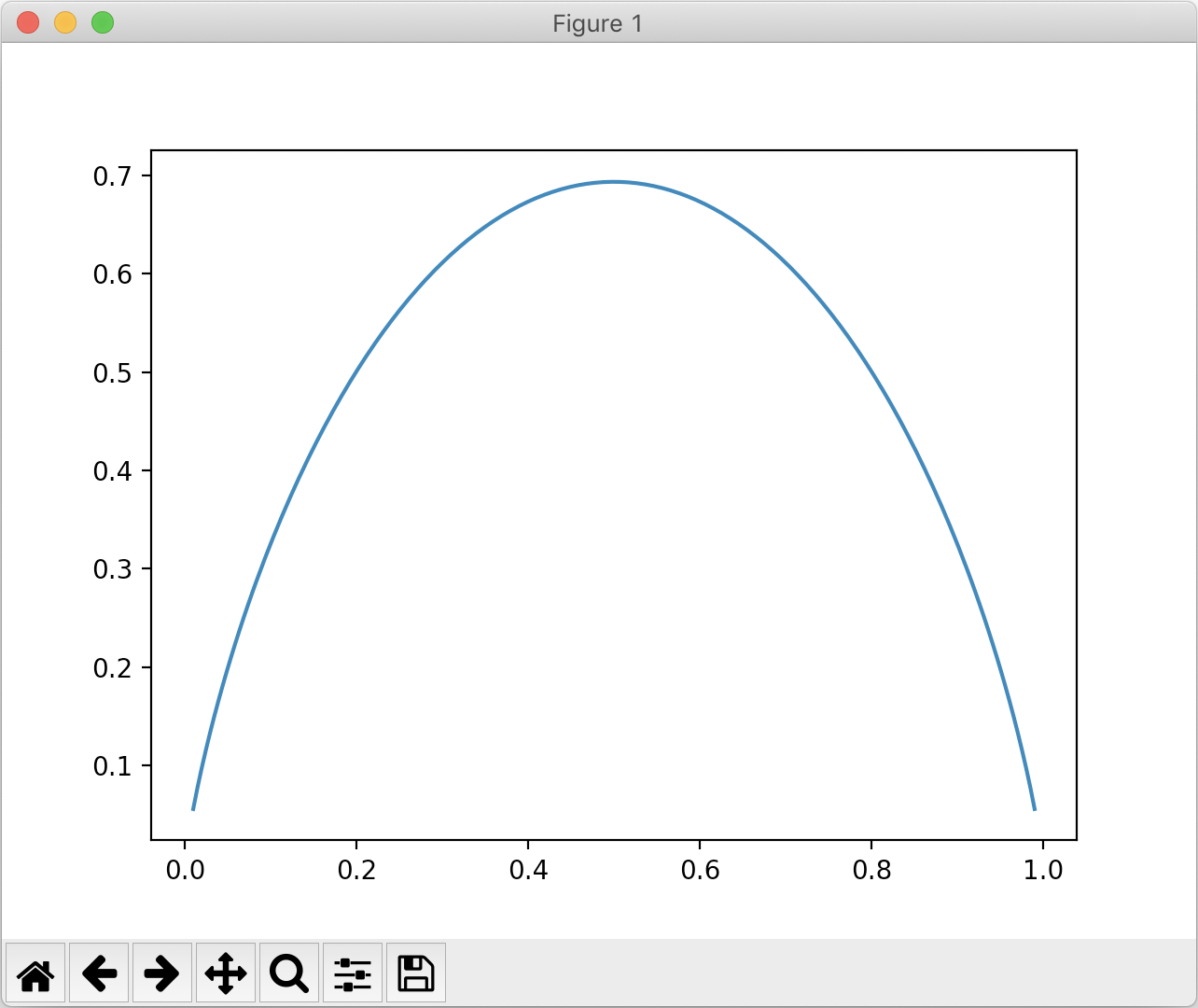
从上图不难看出,在二分类问题中,函数大概以 x=0.5 时为对称轴,并取到最大值(此时数据是最不稳定的)。相对于 0.5,无论 x 值偏大或者偏小,H 值都降低。因为无论 x 值偏向哪一类,数据集中的样本都更集中于一类,数据集的确定性就会偏高。对于多分类问题,信息熵的变化也是类似的,只是无法进行可视化。
更进一步说,当系统中每一个类别是等概率时,是这个系统最不确定的时候(信息熵最高);当系统偏向于某一类(一定程度有了确定性),信息熵会逐渐降低,直到系统完全处于某一类中,此时信息熵达到最低值 0。
提出信息熵后,本节开头提出的两个问题就好说了。在每一个节点上我们都希望在某一个维度上基于某一个阈值进行划分,在数据划分成两部分后我们要让系统整体的信息熵降低(也就是让整个系统变得更加确定。在极端情况下,在叶子节点中的数据都只属于某个特定的类别,此时整个系统的信息熵就达到了 0)。所以说下面的任务就是找在每一个节点上有一个维度,在这个维度上还有一个取值,在这个维度、这个取值对数据进行划分,划分后系统的信息熵是所有其他划分方式得到信息熵的最小值,我们就称这个划分是当前最好的划分。如何找到这个划分呢?我们只要对所有的划分可能性进行搜索就可以了。
三、编程实现信息熵最优的划分和决策树构建
下面我们就进行实际的编程,来模拟一下在一个节点上进行搜索,进而找到在一个节点上基于信息熵最优的划分方式,从而构建决策树。新建一个工程,创建一个main.py文件,实现如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
#进行划分
def split(X, y, d, value):
"""
:param X: 传入待划分的数据集特征
:param y: 传入标记
:param d: 划分的维度
:param value: 相应划分的阈值
:return: 返回划分好的结果
"""
index_a = (X[:,d] <= value) #相应d的值<=value对应的索引
index_b = (X[:,d] > value) #相应d的值> value对应的索引
return X[index_a], X[index_b], y[index_a], y[index_b]
from collections import Counter
from math import log
#计算信息熵
def entropy(y):
"""
:param y: 标记
:return: 返回信息熵
"""
counter = Counter(y) #counter包含了一个字典,键是y的取值(标记),值对应了y这一类分类数据的个数
res = 0.0
#利用公式计算信息熵
for num in counter.values():
p = num / len(y)
res += -p * log(p)
return res
def try_split(X, y):
best_entropy = float('inf') #设置初始的信息熵,初始状态下的信息熵我们认为是无穷大的
best_d, best_v = -1, -1 #在哪个维度、哪个阈值上进行划分
#搜索所有的维度
for d in range(X.shape[1]):
"""确定划分的阈值,对于这些阈值可选的值是每两个样本点在d这个维度上的平均值"""
sorted_index = np.argsort(X[:, d]) #对数据进行索引排序
#对所有样本进行遍历
for i in range(1, len(X)):
if X[sorted_index[i], d] != X[sorted_index[i - 1], d]: #这两个值不应该相等,否则分不开数据
v = (X[sorted_index[i], d] + X[sorted_index[i - 1], d]) / 2 #求i-1和i的均值,作为分割依据
X_l, X_r, y_l, y_r = split(X, y, d, v) #划分后形成了左(l)右(r)两棵子树
p_l, p_r = len(X_l) / len(X), len(X_r) / len(X) #计算划分后左右子树的数据量占比
e = p_l * entropy(y_l) + p_r * entropy(y_r) #计算划分后得到的信息熵,使用加权平均值
#找到更优的划分后更新best
if e < best_entropy:
best_entropy, best_d, best_v = e, d, v
return best_entropy, best_d, best_v
#调用封装好的try_split划分方法,获得一组最好的划分
best_entropy, best_d, best_v = try_split(X, y)
print("best_entropy =", best_entropy) #prints: 0.46209812037329684
print("best_d =", best_d) #prints: 0
print("best_v =", best_v) #prints: 2.45
X1_l, X1_r, y1_l, y1_r = split(X, y, best_d, best_v) #进行实际划分
#打印划分完毕的信息熵
print(entropy(y1_l), entropy(y1_r)) #prints: 0.0 0.6931471805599453
best_entropy2, best_d2, best_v2 = try_split(X1_r, y1_r)
print("best_entropy =", best_entropy2) #prints: 0.2147644654371359
print("best_d =", best_d2) #prints: 1
print("best_v =", best_v2) #prints: 1.75
X2_l, X2_r, y2_l, y2_r = split(X1_r, y1_r, best_d2, best_v2)
print(entropy(y2_l), entropy(y2_r)) #prints: 0.30849545083110386 0.10473243910508653
虽然信息熵还不为零,理论上还可以继续划分。但为了避免过拟合的情况,这里只划分了两次(之前在sklearn中设置的max_depth为2,划分到此为止)。
虽然上面的代码模拟出了利用信息熵进行划分的过程,但这颗决策树并没有建立起来。下面我们用二叉树将这棵决策树构建起来,实现如下:
#时间原因,待补
四、基尼系数
基尼系数的性质与信息熵一样,能够度量随机变量的不确定度的大小。基尼系数的计算比信息熵简单很多,其公式形式如下:
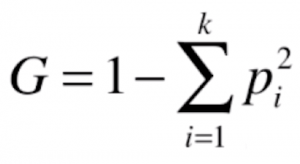
我们和上文一样,举几个具体例子来计算一下基尼系数的结果。依然假设我们数据集中有 3 个类别,3 个类别占比各为1/3,此时的基尼系数就是![]() ,约为0.6666;将三个类别的占比调成,计算结果为
,约为0.6666;将三个类别的占比调成,计算结果为![]() =0.46;将三个类别占比调成
=0.46;将三个类别占比调成![]() ,那么计算结果与信息熵一样也为 0。
,那么计算结果与信息熵一样也为 0。
以二分类任务为例,假设某一类占的比例为 x,那么另外一类就是 1-x,计算得到的基尼系数就是![]() ,化简得
,化简得![]() 。可见基尼系数的函数性质和信息熵类似,均是一个倒 U 型的曲线:当 x = 0.5 时,基尼系数达到最大值,表示此时数据的不确定度最大。
。可见基尼系数的函数性质和信息熵类似,均是一个倒 U 型的曲线:当 x = 0.5 时,基尼系数达到最大值,表示此时数据的不确定度最大。
相应的,我们只要在模拟使用信息熵进行划分的代码中稍加修改,就能使用基尼系数进行划分,实现如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
from collections import Counter
def split(X, y, d, value):
index_a = (X[:, d] <= value)
index_b = (X[:, d] > value)
return X[index_a], X[index_b], y[index_a], y[index_b]
#要将计算信息熵的函数改为计算基尼系数
def gini(y):
counter = Counter(y)
res = 1.0
for num in counter.values():
p = num / len(y)
res -= p ** 2
return res
def try_split(X, y):
best_g = float('inf')
best_d, best_v = -1, -1
for d in range(X.shape[1]):
sorted_index = np.argsort(X[:, d])
for i in range(1, len(X)):
if X[sorted_index[i], d] != X[sorted_index[i - 1], d]:
v = (X[sorted_index[i], d] + X[sorted_index[i - 1], d]) / 2
X_l, X_r, y_l, y_r = split(X, y, d, v)
p_l, p_r = len(X_l) / len(X), len(X_r) / len(X)
g = p_l * gini(y_l) + p_r * gini(y_r) #这里也要相应调用gini函数
if g < best_g:
best_g, best_d, best_v = g, d, v
return best_g, best_d, best_v
#下面的调用代码与信息熵划分完全一致
best_g, best_d, best_v = try_split(X, y)
print("best_g =", best_g) #prints: 0.3333333333333333
print("best_d =", best_d) #prints: 0
print("best_v =", best_v) #prints: 2.45
X1_l, X1_r, y1_l, y1_r = split(X, y, best_d, best_v)
print(gini(y1_l), gini(y1_r)) #prints: 0.0 0.5
best_g2, best_d2, best_v2 = try_split(X1_r, y1_r)
print("best_g =", best_g2) #prints: 0.1103059581320451
print("best_d =", best_d2) #prints: 1
print("best_v =", best_v2) #prints: 1.75
X2_l, X2_r, y2_l, y2_r = split(X1_r, y1_r, best_d2, best_v2)
print(gini(y2_l), gini(y2_r)) #prints: 0.1680384087791495 0.04253308128544431
当然,我们也可以通过基尼系数的划分来生成一棵完整的决策树,实现如下:
#时间原因,待补
五、基尼系数与信息熵的对比
● 信息熵的计算比基尼系数慢(计算信息熵 H 时,需要计算 log(P),而基尼系数只需要计算 P2)。
● 大多数的时候,两者没有特别的效果优劣。