上一篇文章提到了解决模型过拟合问题(模型含有较大的方差)有一种标准的处理手段,就是所谓的模型正则化(Regularization)。模型正则化的作用就是当模型过拟合后,通过限制模型参数的大小来缓解过拟合带来的问题。本文以多项式回归为例,着重讨论模型正则化的一种常用方法——岭回归(Ridge Regression)。
一、岭回归缓解过拟合的基本思路
让我们回到线性回归问题的目标:
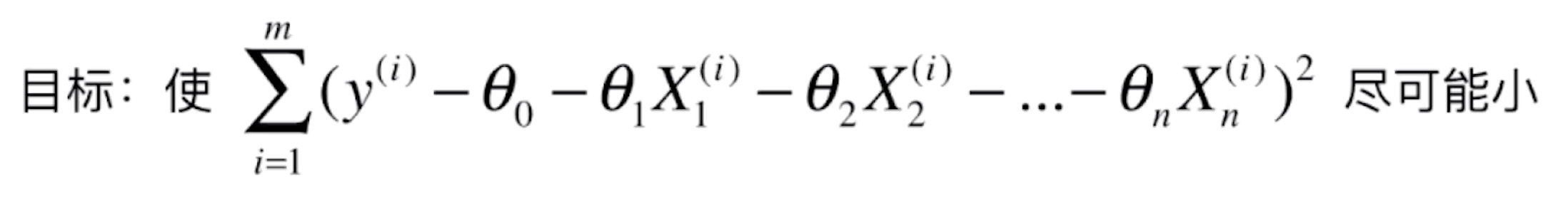
我们求这个式子的最小值,等同于求![]() 的最小值(让原始的数据 y 和用 θ 预测的
的最小值(让原始的数据 y 和用 θ 预测的![]() 的均方误差尽可能小)。如果在这里我们出现了过拟合,θ 这个系数就会非常大,那我们如何让 θ 不那么大呢?答案是改变损失函数,将损失函数变成如下形式:
的均方误差尽可能小)。如果在这里我们出现了过拟合,θ 这个系数就会非常大,那我们如何让 θ 不那么大呢?答案是改变损失函数,将损失函数变成如下形式:
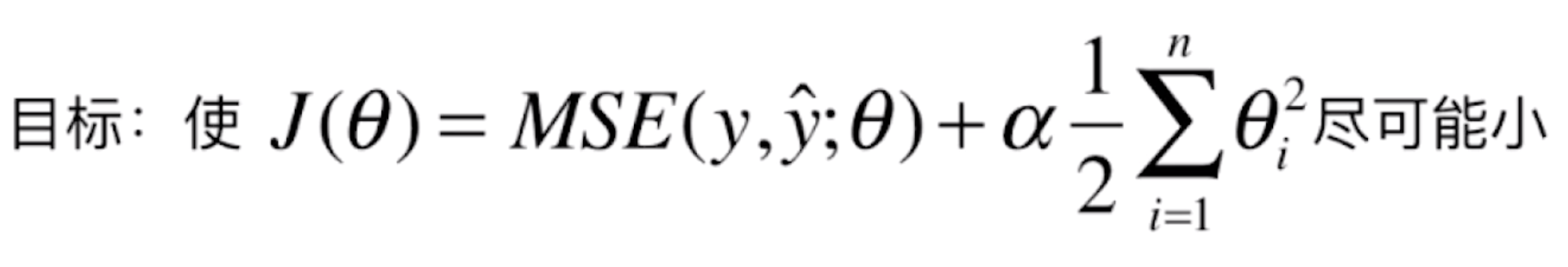
损失函数在原先的基础上加上了一项,加上了所有 θi 的平方和再乘以一个常数(1/2)*α。
我们来分析一下这个式子的意思。首先,我们将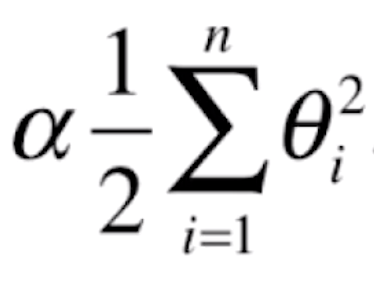 这一“正则化项”加进了目标函数中,现在我们要让 J(θ) 尽可能小就不仅仅要顾及MSE了,还要顾及后面这一项。而后面的这一项是所有 θi 的平方和,所以若要让后面的这一项尽可能小,就只能让每一个 θ 尽可能小。通过这样的方式,我们在最小化 J(θ) 时,相应的就需要考虑让所有的 θ 尽可能小了,就不会出现之前看到的那样每一个 θ 都那么大、曲线那么陡峭的情况,这就是模型正则化的基本原理。加入正则化项来进行模型正则化的方式又被称为“岭回归”。
这一“正则化项”加进了目标函数中,现在我们要让 J(θ) 尽可能小就不仅仅要顾及MSE了,还要顾及后面这一项。而后面的这一项是所有 θi 的平方和,所以若要让后面的这一项尽可能小,就只能让每一个 θ 尽可能小。通过这样的方式,我们在最小化 J(θ) 时,相应的就需要考虑让所有的 θ 尽可能小了,就不会出现之前看到的那样每一个 θ 都那么大、曲线那么陡峭的情况,这就是模型正则化的基本原理。加入正则化项来进行模型正则化的方式又被称为“岭回归”。
这里有几个细节需要注意:
首先
其次,乘以1/2是一个惯例,乘不乘都可以。乘上1/2是因为求解线性回归时运用梯度下降法,需要对 J(θ)进行求导,乘上1/2可以约去后面二次项求导时产生的 2。
最后,α 是模型正则化引入的新的超参数,用于平衡新的损失函数中两部分的关系,代表在模型正则化下新的损失函数中,让每一个 θi 都尽可能的小,这个小的程度占整个优化损失函数程度的多少。当 α = 0,表示目标函数中没有加入模型正则化;当 α 趋向于 +∞ ,目标函数的另一部分 MSE 占整个目标函数的比重非常的小,主要的优化任务就变成了让每一个 θi 都尽可能的小,在极端情况下,只有让 θ都为 0时才能让每一个 θ尽可能小。
最终我们是要在 MSE和使得每一个 θ尽可能小之间取得一个平衡。
二、编程使用岭回归进行模型正则化
新建一个工程,创建一个main.py文件,首先我们先实现一种过拟合的情况,编码如下:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 3 + np.random.normal(0, 1, size=100)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
def PolynomialRegression(degree):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
])
from sklearn.model_selection import train_test_split
np.random.seed(666)
X_train, X_test, y_train, y_test = train_test_split(X, y)
from sklearn.metrics import mean_squared_error
poly_reg = PolynomialRegression(degree=20)
poly_reg.fit(X_train, y_train)
y_poly_predict = poly_reg.predict(X_test)
print(mean_squared_error(y_test, y_poly_predict)) #prints: 167.9401085999025
def plot_model(model):
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(X_plot)
plt.scatter(x, y)
plt.plot(X_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
plot_model(poly_reg)
绘制的图像如下:
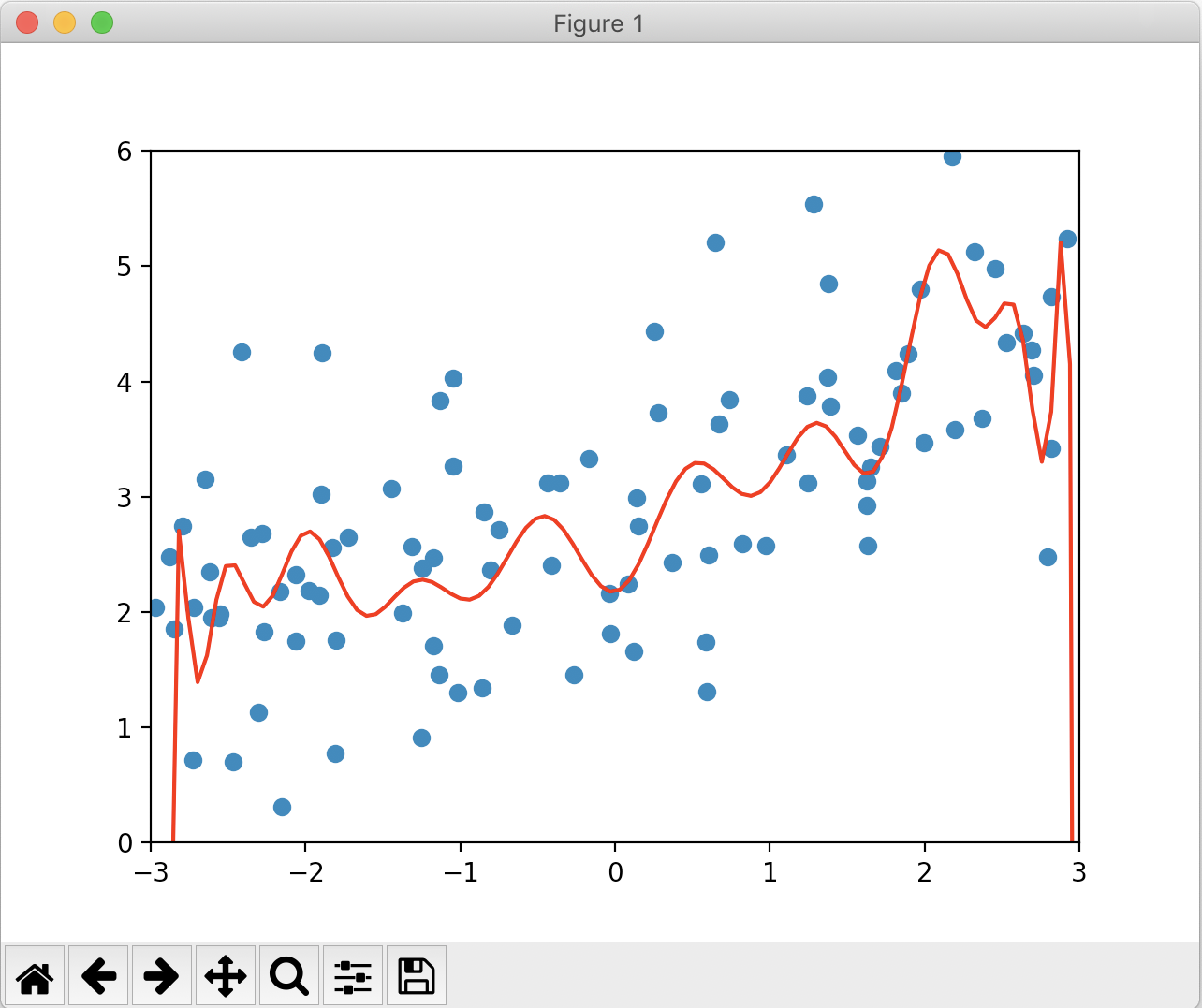
可以看到,不论是打印的MSE和图像,都反映了这是一个过拟合的模型。下面我们使用岭回归来对模型进行正则化,紧接着下面实现如下代码:
from sklearn.linear_model import Ridge
def RidgeRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha=alpha))
])
ridge1_reg = RidgeRegression(20, 0.0001) #先取一个小一些的α值
ridge1_reg.fit(X_train, y_train)
y1_predict = ridge1_reg.predict(X_test)
print(mean_squared_error(y_test, y1_predict)) #prints: 1.3233492754136291
plot_model(ridge1_reg)
绘制的图像如下:
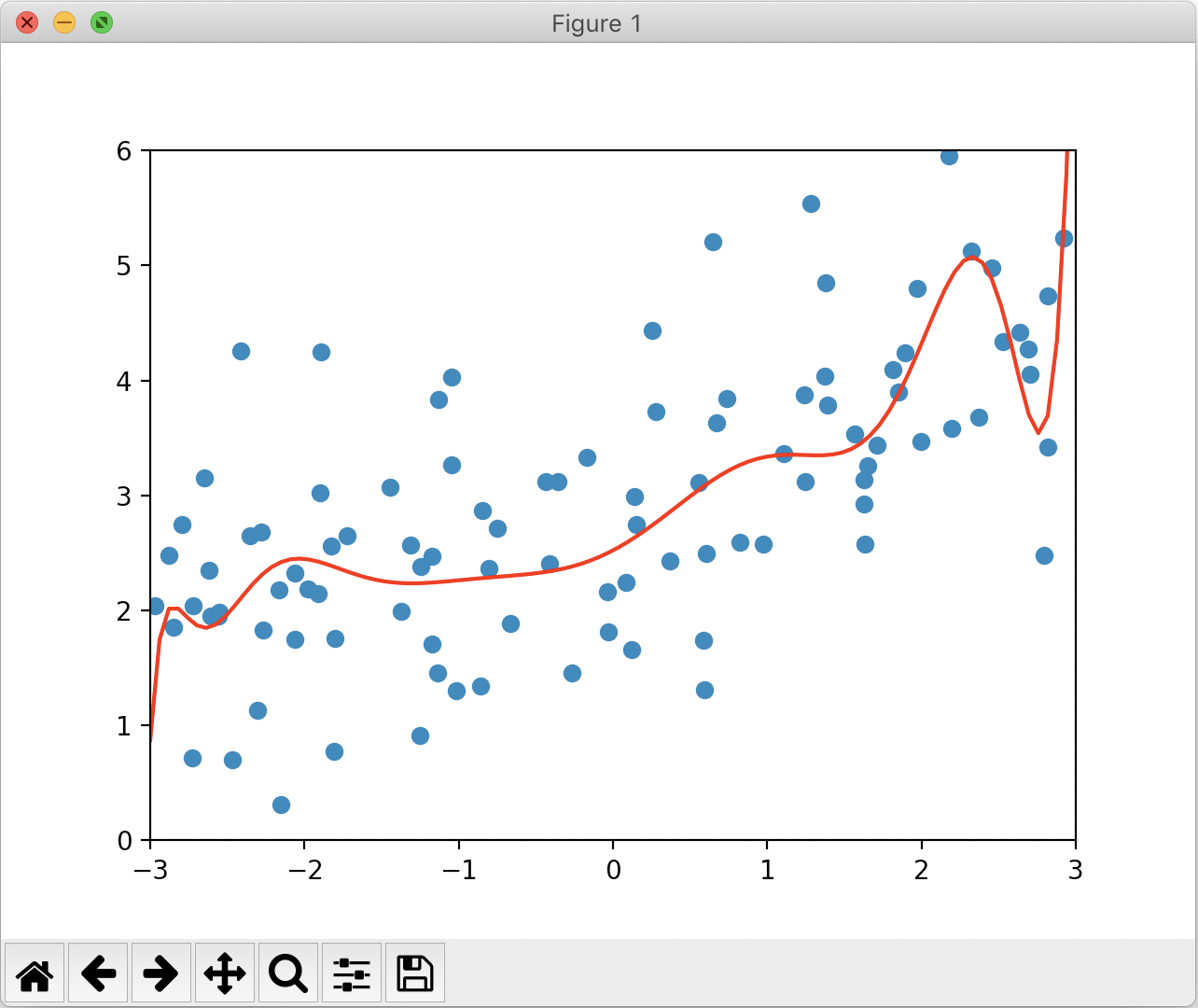
对于多项式回归来说,过拟合所得到的 θ都非常大,甚至达到 10的十几次方这个级别。在岭回归中,由于后面加的这一项为所有 θ的平方和,为了限制 θ,让 θ比较小,α 可以取的小一些,所以我们先取 α为 0.0001来试验,当然更小一些也是可以的。
可以看到,无论是打印的 MSE 还是绘制的图像,过拟合的情况都大大改善,泛化能力也大大提高。我们尝试加大 α 的值,分别取1、100、10000000,绘制的图像如下:
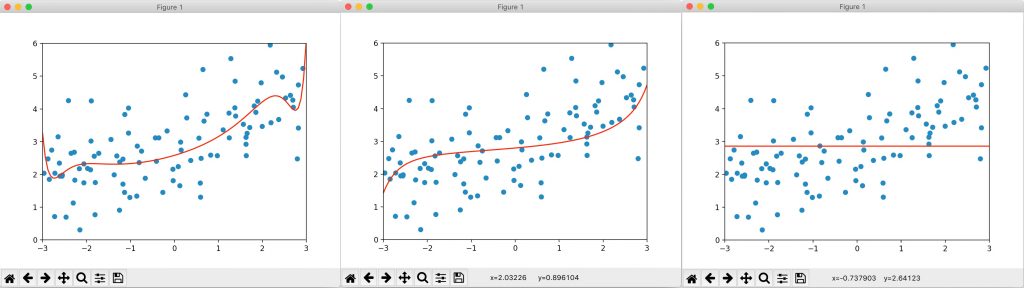
当 α 取1时,MSE 相比于α 取0.0001更小了一些,得到的图像也更接近原本的直线了。继续加大 α 到100时,MSE 反而升高了一些,说明我们的正则化可能有些过头了,在这种情况下曲线变得平滑,没有过多的波折部分了。继续加大 α 到 10000000,一个非常大的值,绘制的图像近乎就是一个平的直线。因为当 α 非常大的时候,对目标函数的影响相当于只有添加的模型正则化在起作用,此时所有的 θ 均为零,也就是与 x 轴平行的直线,它完全没有坡度了。
所以使用岭回归时,也相应的要对 α 进行寻找。α 从小到大,从弯弯曲曲到一根与 x 轴平行的直线,完全与 x 轴平行的直线也并不是我们想要的结果。由此可以看出,α 并不是越大越好的,我们想要的是在中间的一种状态,使得模型的泛化能力达到最佳。