上面我们自己实现了PCA算法,本文将着重探讨sklearn库中PCA的调用和著名的手写数字数据集——MNIST数据集的处理与探索。
一、sklearn中PCA的调用
新建一个工程,创建一个main.py文件,实现以下代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
#加载手写数字数据集
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
#使用kNN分类器进行分类操作
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
print(knn_clf.score(X_test, y_test)) #prints: 0.9866666666666667
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction, y_train)
print(knn_clf.score(X_test_reduction, y_test)) #prints: 0.6066666666666667
在上面的代码中,我们使用kNN算法对这些手写数据集进行分类。其中,第17至19行代码的分类器中我们没有对传入数据进行降维,准确率也比较高,但是在运行中有明显的等待时间;第23至29行代码中,我们将数据降至二维,虽然得出结果时没有等待很久,但是准确率只有60%,这是我们无法接受的。
通过上面的实验,虽然把数据维度降低到二维的同时大大增加了运算效率,但精度太低,我们无法接受。那到底降到多少维合适呢?幸运的是,在 scikit-learn 中的 PCA 算法内,提供了一个指标——pca.explained_variance_ratio_,根据这个指标,可以方便找出针对一个数据集保持多少准确度合适。这个指标返回的数据是各主成分解释原始数据的方差的相应比例,也就是各个主成分所反映原始数据方差的比例,比例越大,说明这个主成分更能代表数据整体的变化。我们可以尝试输出这个属性:
print(pca.explained_variance_ratio_) #prints: [0.14566817 0.13735469]
更准确的说,explained_variance_ratio_ 变量反映的是:该主成分对应的最大时的方差,占原始数据总方差的百分比。
可以看到,我们如果只取二维,得到的这两个主成分只能解释整个数据28%左右的方差,剩下72%就被丢失了,这显然是不合适的。根据上面查看pca.explained_variance_ratio_ 的想法,我们来看一下所有主成分的方差占原始数据总方差的百分比:
pca = PCA(n_components=X_train.shape[1]) #传入所有的维度,即查看所有主成分的方差占原始数据总方差的百分比
pca.fit(X_train)
print(pca.explained_variance_ratio_)
输出结果如下:
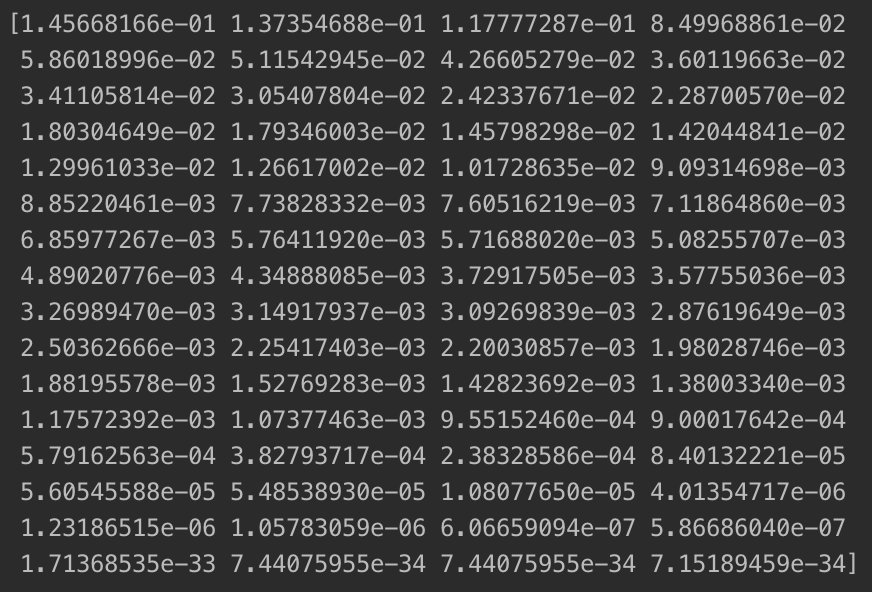
我们通过查看各个主成分能够解释原数据集的方差的比例,可以看出各个主成分的重要程度。我们可以进一步绘图直观的看出这个比例:
plt.plot([i for i in range(X_train.shape[1])],
[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])])
plt.show()
图示如下:

图像的横轴表示前 n 个主成分,纵轴表示这前 n 个主成分所解释的原始数据的方差的比例。通过此曲线,可以判断到底将原始数据降到多少维合适,也就是保留多少原始数据的信息比较合适。我们大致估算一下,当降到30维时,大概是一个合适的位置,在尽可能降维的同时也保留了尽可能多的原始信息。
其实在sklearn中,我们可以在初始化PCA类时可以传入一个0和1之间小数,比如0.95。这代表了我们想做一个PCA,PCA中我不知道我要取多少个主成分,但我取的主成分的个数可以解释我们原来数据95%以上的方差,例如:
pca = PCA(0.95)
pca.fit(X_train)
print(pca.n_components_) #prints: 28
程序自动为我们选取了取前28个主成分,这与我们先前估计的30相近。我们继续计算 n_components_ 取28时的准确率:
pca = PCA(0.95)
pca.fit(X_train)
print(pca.n_components_)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction, y_train)
print(knn_clf.score(X_test_reduction, y_test)) #prints: 0.98
最终得出的98%准确率虽然比用全部样本得出的98.6%要少,但通过降维后大大加快了算法的运行效率,这一点的准确率损失我们是可以接受的。
二、MNIST数据集的加载与使用
新建一个工程,新建一个main.py文件,实现如下代码:
import numpy as np
from sklearn.datasets import fetch_mldata
import time
mnist = fetch_mldata('MNIST original') #下载并导入MNIST数据集
X, y = mnist['data'], mnist['target']
X_train = np.array(X[:60000], dtype=float)
y_train = np.array(y[:60000], dtype=float)
X_test = np.array(X[60000:], dtype=float)
y_test = np.array(y[60000:], dtype=float)
#使用kNN
from sklearn.neighbors import KNeighborsClassifier
start = time.process_time() #使用time模块计时
knn_clf1 = KNeighborsClassifier()
knn_clf1.fit(X_train, y_train)
print(knn_clf1.score(X_test, y_test))
end = time.process_time()
print('Time is %.2f' % (end - start))
#使用PCA进行降维
from sklearn.decomposition import PCA
pca = PCA(0.90)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
start = time.process_time()
knn_clf2 = KNeighborsClassifier()
knn_clf2.fit(X_train_reduction, y_train)
print(knn_clf2.score(X_test_reduction, y_test))
end = time.process_time()
print('Time is %.3f' % (end - start))
使用代码第 5行的fetch_mldata函数时,会提示该方法被弃用从而无法下载 mnist数据集,可以点击这里下载。对于Mac系统,只要把下载下来的文件放在 ~/scikit_learn_data/mldata目录下再运行程序即可。由于笔者不使用Windows系统,暂时不清楚Windows系统的放置目录,读者可自行采用搜索引擎搜索解决。
当然,我们也可以用最新的方法 fetch_openml获得 mnist数据集,方法如下:
from sklearn.datasets import fetch_openml mnist = fetch_openml('mnist_784')只需要把上面代码中获得 mnist 的方式改成上面代码就可以,其他代码不变。
上面的代码中我们实例化了两个kNN分类器,其中knn_clf1没有进行降维,knn_clf2对数据进行了降维并保留了90%的信息。运行工程,等待一段时间后,输出结果如下:
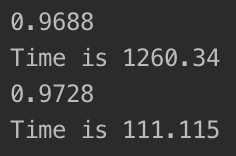
我们还可以尝试打印降维前后数据的维数:
print(X_train.shape) #prints: (60000, 784)
print(X_train_reduction.shape) #prints: (60000, 87)
我们可以看到,把一个784维的数据降到87维,不仅仅算法运行的速度大大加快,准确率也提升了一些。降维前花了二十多分钟的时间,准确率达到了96.88%,而降维后的数据的运行速度快了十多倍,准确率反而提高了一些(是由于PCA降维的同时把噪音也消除了),可见PCA降维的威力。