简单线性回归算法只有一个特征值(x),但是在真实世界中,我们的样本通常是有成千上万个特征值的。针对这样的样本,我们可以使用多元线性回归来求解。多元线性回归中有多种特征,每一种特征都与 y 呈线性关系,只是线性关系的系数不同。下面就让我们看一下多元线性回归的求解思路以及算法实现。
一、多元线性回归的求解思路
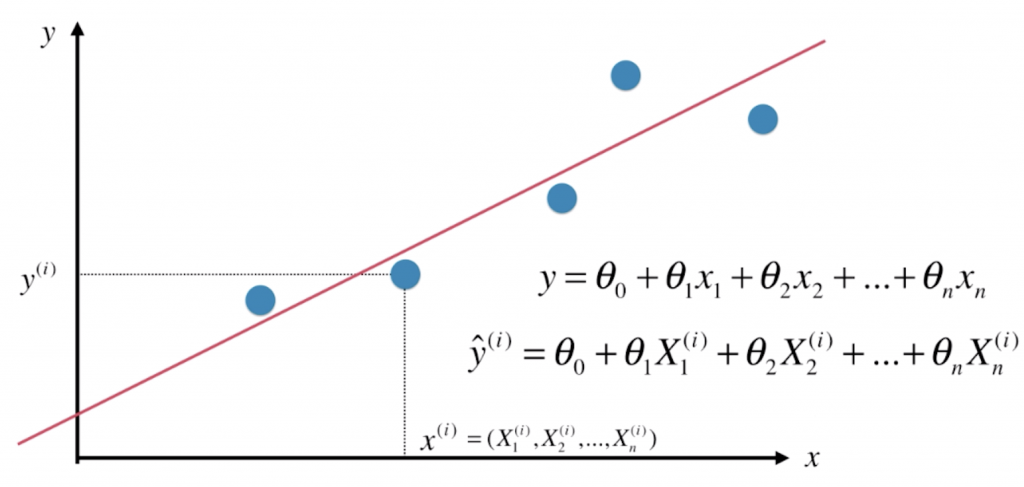
与简单线性回归不同,多元线性回归的每一个点x(i)对应一个向量。可以理解为:我们本来有一个大的数据集X,每一行表示一个样本,每一列表示一个特征。那么![]() 表示X中第i行这个样本,X1(i), X2(i), X3(i), … 表示这个样本的特征。我们直线的方程就可以写为
表示X中第i行这个样本,X1(i), X2(i), X3(i), … 表示这个样本的特征。我们直线的方程就可以写为 ![]() ,其中我们的数据有多少个特征(维度),相应的就有多少个θ(每一个维度前面都有一个系数),并且这条直线的截距我们记作θ0。其实所谓“简单线性回归”,就是只要学习θ0和θ1就好了,但多元线性回归时,我们就要学习“n+1”个参数。相对应的,多元线性回归的预测值可以写为
,其中我们的数据有多少个特征(维度),相应的就有多少个θ(每一个维度前面都有一个系数),并且这条直线的截距我们记作θ0。其实所谓“简单线性回归”,就是只要学习θ0和θ1就好了,但多元线性回归时,我们就要学习“n+1”个参数。相对应的,多元线性回归的预测值可以写为![]() 。
。
我们求解多元线性回归的思路也和简单线性回归一致:对于简单线性回归,我们的目标是使(y(i) –![]() (i))2尽可能小,多元线性回归也是如此,只不过我们的预测值变成了
(i))2尽可能小,多元线性回归也是如此,只不过我们的预测值变成了![]() ,那我们的目标就转化为:
,那我们的目标就转化为:
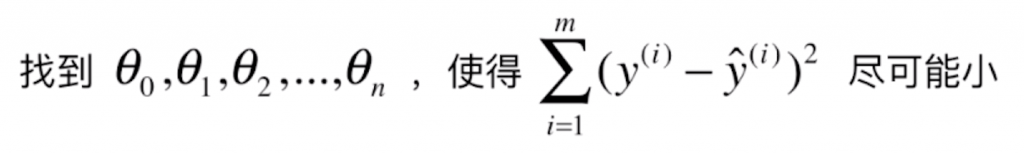
仔细观察![]() ,我们把要学习的 θ0, θ1, θ2, …,θn 整理成一个向量
,我们把要学习的 θ0, θ1, θ2, …,θn 整理成一个向量![]() ,在
,在![]() (i)的表达式中我们稍作修改成
(i)的表达式中我们稍作修改成![]() ,新增一个恒等于1的“第0个特征”,便于我们推导。这时我们就可以将数据集X中的第i个样本X(i)设成行向量
,新增一个恒等于1的“第0个特征”,便于我们推导。这时我们就可以将数据集X中的第i个样本X(i)设成行向量![]() ,那我们对第i行样本的预测值就可以表示为
,那我们对第i行样本的预测值就可以表示为![]() 。
。

我们将结论推广到所有的样本上,我们设矩阵Xb为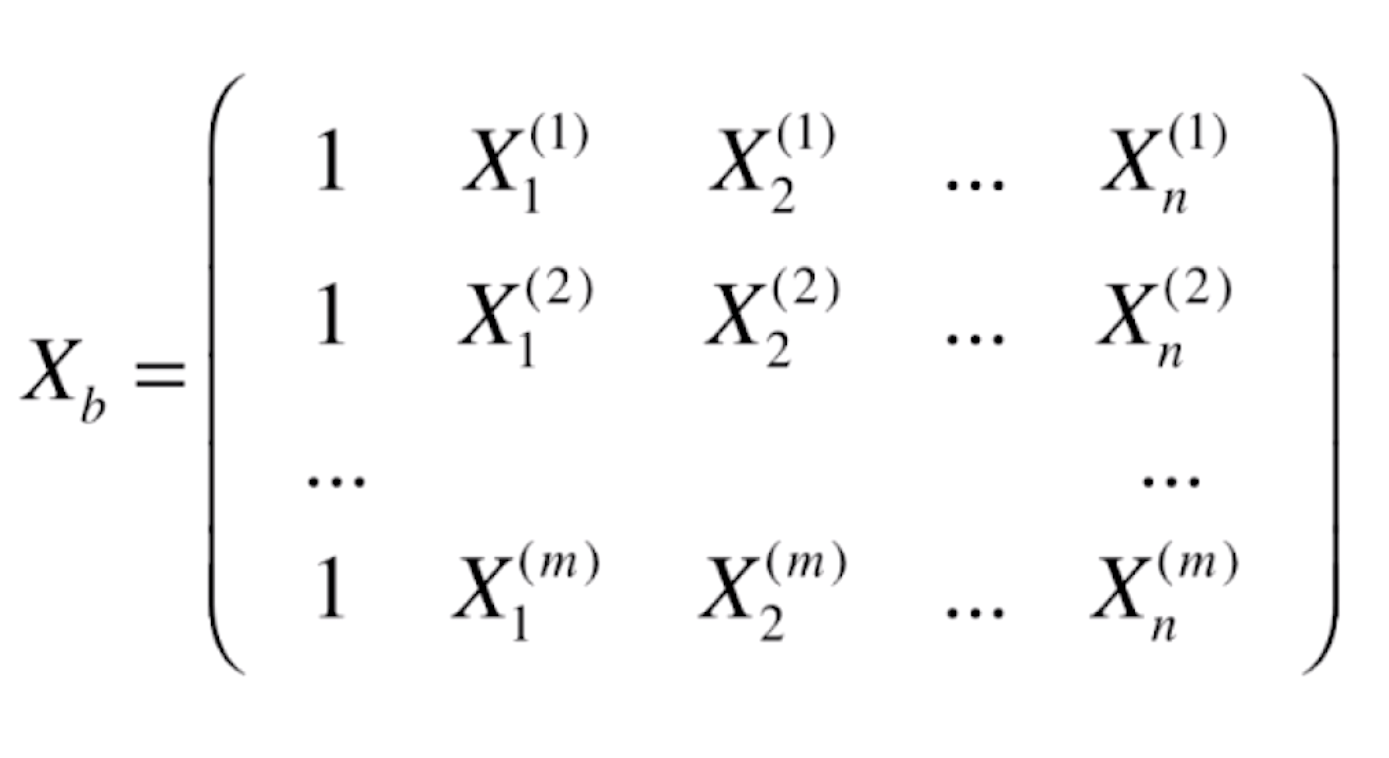 ,相比较原数据集X新增了一列“1”,并且对
,相比较原数据集X新增了一列“1”,并且对![]() 加以推广,得到
加以推广,得到![]() = Xb · θ。其中,
= Xb · θ。其中,![]() 是一个列向量,它一共有m个元素,每一个元素是我们使用多元线性回归法得到θ这个参数后,X中每一个样本预测的结果,通过矩阵乘法的性质可以很容易证明这一点。
是一个列向量,它一共有m个元素,每一个元素是我们使用多元线性回归法得到θ这个参数后,X中每一个样本预测的结果,通过矩阵乘法的性质可以很容易证明这一点。
我们继续把问题转换成:求一个满足![]() = Xb · θ的向量
= Xb · θ的向量![]() ,使得
,使得![]() 尽可能小。注意到(y(i) –
尽可能小。注意到(y(i) –![]() (i))实际上是一个向量,平方之后就是这个向量模长。将
(i))实际上是一个向量,平方之后就是这个向量模长。将![]() = Xb · θ代入,“使
= Xb · θ代入,“使![]() 尽可能小”就等价于“使
尽可能小”就等价于“使![]() 尽可能小(注意符号的变化,去掉了求和符号)”。
尽可能小(注意符号的变化,去掉了求和符号)”。
如何求![]() 的最小值时θ是多少呢?这实际上和简单线性回归是类似的,也是使用最小二乘法的原理,不过这边变成了对矩阵进行求导运算。由于在博客中不方便直接打出公式,我们直接给出答案:
的最小值时θ是多少呢?这实际上和简单线性回归是类似的,也是使用最小二乘法的原理,不过这边变成了对矩阵进行求导运算。由于在博客中不方便直接打出公式,我们直接给出答案:
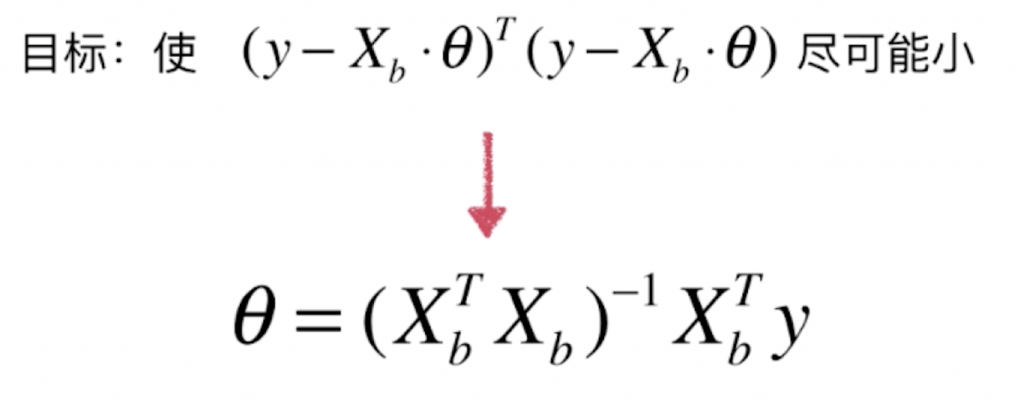
这个式子看起来非常好,我们通过监督学习的数据可以非常方便地计算出结果,但其实这个式子求解的时间复杂度是比较高的,达到了O(n3),即使通过矩阵运算的性质优化后也会在O(n2.4)这个水平。但我们具体实际实现时会采用另一种解决方法,在后面的文章会提到。得到式子好处是我们顺利得出了多元线性回归的数学解,这也就意味着我们无需对数据进行归一化处理。
二、编程实现多元线性回归
我们在上一篇文章的MyML包中添加一个LinearRegression.py文件,在里面实现如下代码:
import numpy as np
from .metrics import r2_score
class LinearRegression:
def __init__(self):
#初始化Linear Regression模型
self.coef_ = None #每个属性系数,即θ1, θ2, ...,θn
self.intercept_ = None #拟合直线的截距,即θ0
self._theta = None #coef_与intercept_合并产生的θ0, θ1, θ2, ...,θn
def fit_normal(self, X_train, y_train):
#根据训练数据集X_train, y_train训练Linear Regression模型
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) #给数据集X的坐标加上一列全为"1"的数据
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train) #根据我们推导的多元线性回归正规方程解求出θ
self.intercept_ = self._theta[0] #直线截距即为_theta的第0个元素
self.coef_ = self._theta[1:] #_theta后面的元素均为每个属性之前的系数
return self
def predict(self, X_predict):
#给定待预测数据集X_predict,返回表示X_predict的结果向量
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
#根据测试数据集 X_test 和 y_test 确定当前模型的准确度
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict) #利用R Squared方法确定准确度
def __repr__(self):
return "LinearRegression()"
新建一个main.py文件,实现如下代码:
import numpy as np
from sklearn import datasets
boston = datasets.load_boston() #依然加载波士顿房价数据集
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from MyML.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
from MyML.LinearRegression import LinearRegression
reg = LinearRegression()
reg.fit_normal(X_train, y_train)
print(reg.coef_) #打印系数
print(reg.intercept_) #打印截距
print(reg.score(X_test, y_test)) #打印准确率
在十三维空间中我们不能将数据可视化,但我们可以打印出线性拟合的结果:
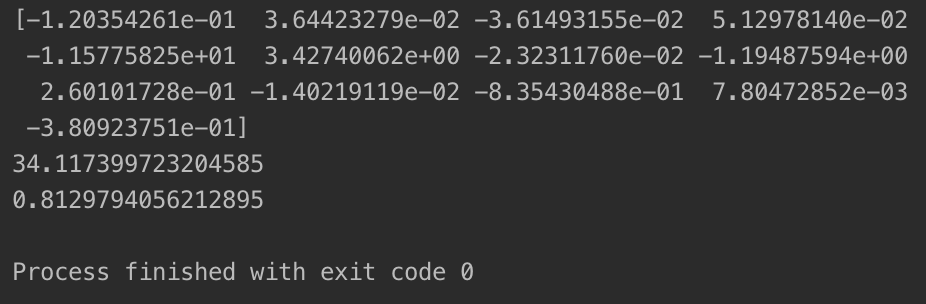
可以看到,在考虑其他属性进行多元线性回归后,预测准确率有着明显的提升,达到了81.3%左右。
一般 θ向量中各分量的值反映了y受对应属性的影响程度。若为正,则对应属性对y成正相关;若为负,则对应属性对y成负相关。绝对值越大,代表y值受这个属性的影响也就越大。例如上图中,第 2、4、6、9、12个属性对房价成正相关,其他属性对房价成负相关,且第 5和第 4个属性分别对房价的正面、负面影响最大。
三、使用sklearn中的线性回归与kNN算法预测波士顿房价
sklearn中同样为我们封装好了线性回归的类,我们可以直接方便的调用其中为我们封装好的方法。修改main.py,具体实现如下:
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from MyML.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
print(lin_reg.coef_)
print(lin_reg.intercept_)
print(lin_reg.score(X_test, y_test))
结果应该与我们自己实现的代码相同。前面的文章我们提到,kNN算法也能解决回归问题。我们紧挨着上面的代码创建一个kNN回归器,实现如下:
#进行数据归一化
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train, y_train)
X_train_standard = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)
#初始化kNN回归器
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor()
#进行调参
from sklearn.model_selection import GridSearchCV
param_grid = [
{
"weights": ["uniform"],
"n_neighbors": [i for i in range(1, 11)]
},
{
"weights": ["distance"],
"n_neighbors": [i for i in range(1, 11)],
"p": [i for i in range(1,6)]
}
]
knn_reg = KNeighborsRegressor()
grid_search = GridSearchCV(knn_reg, param_grid, n_jobs=-1, verbose=1)
grid_search.fit(X_train_standard, y_train)
print(grid_search.best_params_) #打印网格搜索得出的最佳参数
#print(grid_search.best_score_) 这个score是在CV中运用交叉验证得出来的,没有可参考性,我们应以下面的score为准
print(grid_search.best_estimator_.score(X_test_standard, y_test))
kNN算法中,最佳模型和参数,是根据对比GridSearchCV()内部的逻辑运算(best_score_)所得到的准确度而确定的,不是kNN算法(KNeighborsClassifier()、KneighborsRegressor()等)中的score()函数;两种方式的内部逻辑是不同的。
运行结果如下:
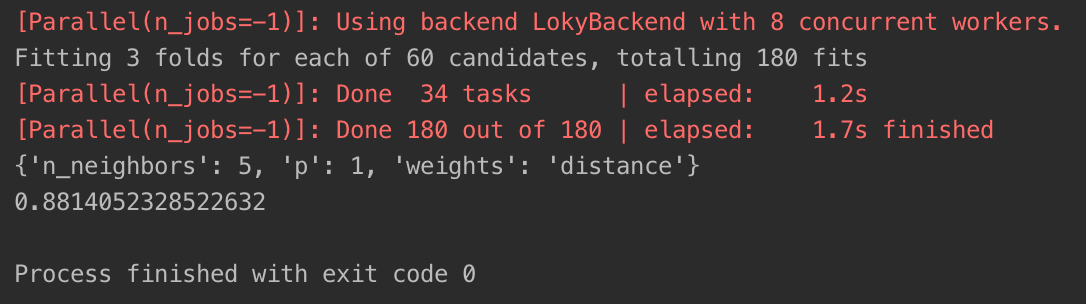
我们发现,使用网格搜索优化后的kNN算法的准确率比多元线性回归还要高,达到了88.1%,足以看出kNN算法的强大之处。
使用机器学习算法解决问题时,会用不同的算法得到不同的准确度,比较算法优劣时,不能很武断的做判断,要细心考虑不同算法对准确度计算方式,因为同一个算法通过不同的方式可以得到不同的准确度:grid_search.best_score_、grid_search.best_estimator_.score(X_test, y_test),同一个算法模型,使用不同的方式得出的准确度不同。