上一篇文章中对kNN算法进行了初步的实现,并将其封装到了一个模块当中便于使用:
#文件名:main.py
from sklearn import datasets
from kNNmodule.model_selection import train_test_split
from kNNmodule.kNN import KNNClassifier
iris = datasets.load_iris() #加载著名的鸢尾花数据集
"""
sklearn中,datasets的鸢尾花数据集一共有五个部分组成,分别为:
data(鸢尾花的特征矩阵)
target(结果标签对应的向量)
targetnames(标记所对应的鸢尾花的名字)
DESCR(描述,即该数据集的文档)
feature_names(三种鸢尾花的特征所对应的的名字)
"""
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
my_knn_clf = KNNClassifier(k=3)
my_knn_clf.fit(X_train, y_train)
y_predict = my_knn_clf.predict(X_test)
print(y_predict)
print(y_test)
print(sum(y_predict == y_test)) #打印预测准确的个数
print(sum(y_predict == y_test) / len(y_test)) #打印预测的准确率 在上述代码的第24行中,我们实例化了一个kNN分类器,并传入了一个参数“ k ”,代表在训练数据集中去找与该实例最邻近的 k 个实例。但是,我们如何确定这个“ k ”的值是最好的、最能符合模型呢?这就涉及到了机器学习领域的一个非常重要的概念——超参数。
一、什么是超参数
所谓超参数,就是在开始学习过程之前已经设置好的参数,而不是通过训练得到的参数数据(通过训练得到的参数数据被称为“模型参数”)。通常情况下,我们需要给我们的机器学习算法选择一组最优超参数,以提高学习的性能和效果。我们经常听说机器学习算法工程师经常做的一个工作叫“调参”,实际上这个“调参”调的就是超参数。在kNN算法中,没有模型参数,而“ k ”这个参数就是kNN算法中非常典型的超参数。
二、如何寻找最优的超参数
我们通常使用以下三种方法来确定最优的超参数:
● 领域知识:在某个特定领域的问题中有对应的最优超参数
● 经验数值:根据自己或他人调参的经验确定最优超参数
● 实验搜索
在具体问题中,我们可能无法通过领域知识或者经验数值来确定最优超参数,这时我们就要采用实验搜索的办法,尝试测试几组不同的超参数来找出最优值,最终在我们的模型中使用这些值。
下面我们新建一个工程,直接使用机器学习框架sklearn封装好的函数来实现最优超参数“ k ”的寻找。在工程中新建一个main.py文件,实现如下:
import numpy as np
from sklearn import datasets
digits = datasets.load_digits() #这里采用了一套sklearn预设的手写数字0至9的数据集
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k =", best_k)
print("best_score =", best_score)
输出结果如下所示:
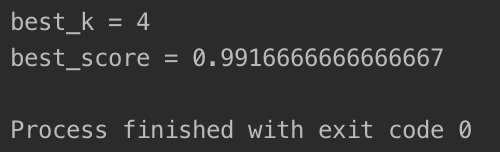
我们顺利的找出了最佳的 k 值 4 ,此时的预测准确率为99.17%左右。
kNN算法中的距离度量是kNN算法中的另外一个超参数,也就是将待预测点与其最近的 k 个点的距离纳入考量范围内,距离越短的点权重越大。若要将距离考虑进去,可以这样编写程序:
best_score = 0.0
best_k = -1
best_method = ""
for method in ["uniform", "distance"]: #其中uniform不考虑距离,distance考虑距离
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_method =", best_method)
print("best_k =", best_k)
print("best_score =", best_score)
输出结果如下图所示:
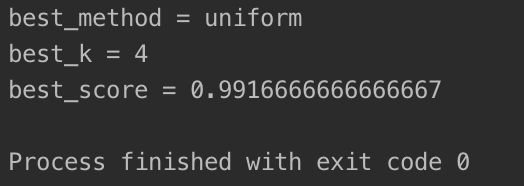
我们在找出最佳 k = 4 的同时也发现不考虑距离的时候,对于这个机器学习算法来说效果更好一些。
三、网格搜索
kNN算法本身还有着其他的超参数,这种在所有候选的参数中,通过循环遍历,尝试每一种可能性,找出表现最好的参数并作为最终结果的方法被称为网格搜索(Grid Search)。若我们像上面一样,每搜索一个参数就嵌套一层for循环,会显得杂乱。幸运的是,sklearn为我们封装好了网格搜索的函数,便于增强代码的易读性,代码实现如下:
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
#定义需要网格搜索的超参数,定义的结构类似于json
param_grid = [
{
'weights': ['uniform'],
'n_neighbors': [i for i in range(1, 11)] #k的值
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)] #p为明可夫斯基距离中的参数p
}
]
knn_clf = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
#n_jobs属性为运行网格搜索所使用的CPU核心数,-1为全部使用;verbose属性为显示网格搜索运行过程,0或默认值为不显示,数字越大显示的内容越详细
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
print(grid_search.best_estimator_) #打印最佳的超参数
print(grid_search.best_score_) #打印采用最佳超参数时,预测的准确率
运行结束后,会得出网格搜索的结果:
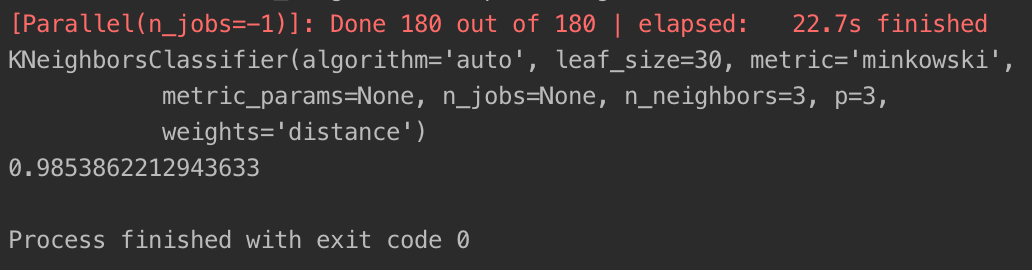
通过打印grid_search.best_estimator_属性,我们很容易就能看出所有超参数的最佳值,从而避免了手动调参的麻烦。