k近邻算法(K-Nearest Neighbor,简称kNN)是机器学习中的一种基本分类和回归方法。我们给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分类到这个类中(类似于现实生活中少数服从多数的思想)。根本思想就是:两个样本,如果它们的特征足够相似,它们就有更高的概率属于同一个类别,我们要做的就是根据现有训练数据集,判断新的样本属于哪种类型。
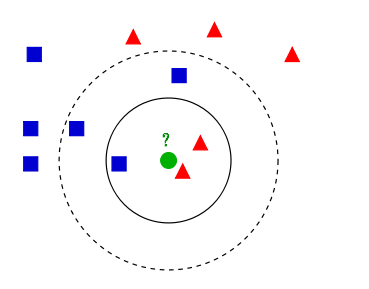
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个问号绿点所标示的数据则是待分类的数据。这也就是我们的目的:来了一个新的数据点,我们要判断这个数据点属于红色或蓝色数据的哪一类。在kNN算法的思想中,我们可以做如下处理:
● 如果我们取k=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,判定绿色的这个待分类点属于红色的三角形这一类。
● 如果我们取k=5,绿色圆点的最邻近的5个点是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形这一类。
从上面例子我们不难看出,k近邻的算法思想非常的简单,也非常的容易理解,几乎用不到什么数学知识,只要求新的数据点离最近的k个点的距离之和即可。基于上面的论述,我们就可以进行编码了。我们将整个kNN分类器封装成一个类,以PyCharm作为IDE,加载anaconda解释器,编写如下代码:
#文件名:kNN.py
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k): #kNN分类器的构造函数
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train): #根据训练数据集X_train和y_train训练kNN分类器
assert X_train.shape[0] == y_train.shape[0], \
"The size of X_train must be equal to the size of y_train."
assert self.k <= X_train.shape[0], \
"The size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict): #给定待预测数据集X_predict,返回表示X_predict的结果向量
assert self._X_train is not None and self._y_train is not None, \
"Must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"The feature number of X_predict must be equal to X_train."
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x): #给定单个待预测数据x,返回x的预测结果值
assert x.shape[0] == self._X_train.shape[1], \
"The feature number of x must be equal to X_train."
#计算待预测数据x到数据集各点的距离,存在distances数组中
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in self._X_train]
nearest = np.argsort(distances) #根据索引进行排序
topK_y = [self._y_train[i] for i in nearest[:self.k]] #找出距离最短的k个点
votes = Counter(topK_y) #统计距离最短的k个点中每个标记出现的频率
return votes.most_common(1)[0][0] #返回出现频率最高的标记
def __repr__(self): #定义显示方法,返回当前对象的k值
return "kNN(k=%d)" % self.k
这样我们就实现了一个简单的kNN的分类器,原则上我们就可以使用这个类进行实地的预测了。然而我们忽视了一个问题——通常机器学习算法中,需要将整个数据集的大部分作为训练集,再把小部分作为测试集。我们要编写对数据集的分割代码,实现如下:
#文件名:model_selection.py
import numpy as np
#将数据 X 和 y 按照test_ratio分割成X_train, X_test, y_train, y_test
def train_test_split(X, y, test_ratio = 0.2, seed = None):
assert X.shape[0] == y.shape[0], \
"The size of X must be equal to the size of y."
assert 0.0 <= test_ratio <= 1.0, \
"Test_ration must be valid."
#在debug时若需要在运行中生成相同的训练集和测试集,则指定随机数种子
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X)) #将数据集的顺序打乱(打乱索引)
#确定训练集和数据集的索引范围
test_size = int(len(X) * test_ratio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
#使用numpy的fancy indexing来构建训练集和测试集矩阵
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
现在我们已经成功创建了一个简单的kNN算法的模块,我们以下图的方式把这三个文件拖入一个文件夹中,便于我们后续的调用。

在PyCharm工程的根目录下新建一个main.py文件,在其中写入以下代码,用著名的鸢尾花(iris)数据集来验证我们的算法:
#文件名:main.py
from sklearn import datasets
from kNNmodule.model_selection import train_test_split
from kNNmodule.kNN import KNNClassifier
iris = datasets.load_iris() #加载著名的鸢尾花数据集
"""
sklearn中,datasets的鸢尾花数据集一共有五个部分组成,分别为:
data(鸢尾花的特征矩阵)
target(结果标签对应的向量)
targetnames(标记所对应的鸢尾花的名字)
DESCR(描述,即该数据集的文档)
feature_names(三种鸢尾花的特征所对应的的名字)
"""
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
my_knn_clf = KNNClassifier(k=3)
my_knn_clf.fit(X_train, y_train)
y_predict = my_knn_clf.predict(X_test)
print(y_predict)
print(y_test)
print(sum(y_predict == y_test)) #打印预测准确的个数
print(sum(y_predict == y_test) / len(y_test)) #打印预测的准确率
打印的结果如下:
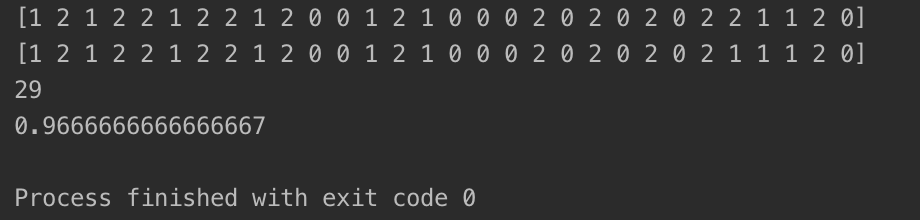
至此,我们成功实现了kNN算法。可以看到,kNN算法在k=3时对鸢尾花数据集的预测准确率非常高,约为96.7%。